
Wikipedia:Link rot/URL change requests/Archives/2019/October
| This is an archive of past discussions on Wikipedia:Link rot. Do not edit the contents of this page. If you wish to start a new discussion or revive an old one, please do so on the current main page. |
Update reference urls
(section moved from WP:BOTREQ)
Hi. The URL's for Dictionary of Welsh Biography entries have recently changed. Is there any chance you can update them on en Wiki for me?
The old Refs begin http://yba.llgc.org.uk/en/ - followed by a persistent i.d. and then .html. For example - http://yba.llgc.org.uk/en/s2-DAVI-THO-1899.html
This first section needs to be replaced with https://biography.wales/article/ and .html removed from the end. So that the new url is as follows https://biography.wales/article/s2-DAVI-THO-1899
There should be a few hundred of these around Wiki, but i cant seem to find a tool to track them all down. Please ping me if you need any other information. Thanks! Jason.nlw (talk) 07:48, 26 March 2019 (UTC)
- There's about a thousand of these. Galobtter (pingó mió) 11:26, 26 March 2019 (UTC)
- @Jason.nlw: courtesy ping, please see above. --TheSandDoctor Talk 14:36, 26 March 2019 (UTC)
I can do this. I have a tool designed to work with URL modifications and various templates including handling of archive URLs. -- GreenC 14:50, 26 March 2019 (UTC)
- Thanks all. GreenC It would be great if you could. Many thanks! Jason.nlw (talk) 14:58, 26 March 2019 (UTC)
- @Jason.nlw: - this is
 Done -- GreenC 17:39, 27 March 2019 (UTC)
Done -- GreenC 17:39, 27 March 2019 (UTC)
- @Jason.nlw: - this is
sciencedirect.com
(copied from User_talk:GreenC#Broken_links_to_www3.interscience.wiley.com)
I found another 3000 or so pages with URLs beginning http://www.sciencedirect.com/science?_ob=ArticleURL which, based on a random samples checked with lynx, are all broken... These should be removed as well. Nemo 18:25, 10 March 2019 (UTC)
- Nemo, copied this request to the new URLREQ noticeboard. Have not forgotten. -- GreenC 17:33, 27 March 2019 (UTC)
- @Nemo bis: - this is done. I did spend a lot of time trying to figure out the best way to delete the URLs but the problem is messy. Sometimes the DOI URL reports status 200 but returns an error page (a soft-404) so it's very difficult to determine when the
|archive-url=is the same as the|doi=URL and safe to delete. It is also concerning that doi.org is not reliable so maintaining the|archiveurl=seems like a conservative safe approach for the long term. -- GreenC 15:05, 31 March 2019 (UTC)
pmsa.org
(copied from User_talk:Cyberpower678#IABot_query)
Pages on the PMSA website beginning http://www.pmsa.org.uk/pmsa-database/ have been deleted; I wanted to get IABot to swap them for archived versions, but can't figure out how to do so. Can you either point me at a guide, or add the task, please? Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 11:31, 26 March 2019 (UTC)
- @Pigsonthewing: - will work on this. -- GreenC 17:36, 27 March 2019 (UTC)
- @Pigsonthewing: - this is done. Turned out everything *.pmsa.org.uk/* was dead. IABot database also updated globally. -- GreenC 04:02, 1 April 2019 (UTC)
hem.passagen.se
This domain, referenced in over 1,000 articles, now links to an online betting site. Could the links please be archived or removed?: Bhunacat10 (talk), 10:53, 30 March 2019 (UTC)
- Working.. -- GreenC 15:55, 31 March 2019 (UTC)
- @Bhunacat10: Done and updated IABot database. -- GreenC 02:54, 1 April 2019 (UTC)
amanet-trust.org
I think www.amanet-trust.org is likely only mentioned on African Malaria Network Trust, but it's the official page & now links to an installer of some type. Not sure if "dead link" is enough?
Thanks Deadstar (talk) 11:33, 24 April 2019 (UTC)
- Deadstar, two links in African Malaria Network Trust and one in Agaro (already archived), I manually added archives in AMNT. -- GreenC 13:02, 24 April 2019 (UTC)
- Thank you. Deadstar (talk) 19:32, 24 April 2019 (UTC)
newenglandwild.org -> nativeplanttrust.org
The New England Wild Flower Society [1] changed its name and web presence to the Native Plant Trust [2]. And in the process broke most of its old URLs. Insecure http requests to the old web site get an HTTP 301 redirect. https requests time out. I suspect a firewall misconfiguration on their end, but I emailed about the problem and it hasn't been fixed.
I am requesting a bot find all the instances of DOMAIN.newenglandwild.org/PATH (http or https) and rewrite to DOMAIN.nativeplanttrust.org/PATH (https only, optionally only if that new URL returns a 2xx or 3xx status code).
There are about 100 edits to make. Here is a sample page: Vaccinium caesariense. As I write this, reference 2 links to https://gobotany.newenglandwild.org/species/vaccinium/caesariense/ (a timeout error). It should link to https://gobotany.nativeplanttrust.org/species/vaccinium/caesariense/. Vox Sciurorum (talk) 22:44, 17 May 2019 (UTC)
- I have changed all of the links in article space, but I recommend replacing nearly all of them with the Go Botany template. That will have to be done manually. – Jonesey95 (talk) 07:48, 18 May 2019 (UTC)
Lists of Billboard Hot Latin Songs number-one songs
I've been doing dead link repair of late and List of number-one Billboard Hot Latin Tracks of 1997 came to my attention today. At some point, the URLs apparently changed from http://www.billboard.com/charts/yyyy-mm-dd/latin-songs to http://www.billboard.com/charts/latin-songs/yyyy-mm-dd, where yyyy-mm-dd is the year/month/day of the chart release. I fixed the links in the 1997 page, but there are 395 others that have the same old style url. I wouldn't be surprised if something similar is going on with articles about other Billboard charts. --sanfranman59 (talk) 18:55, 23 May 2019 (UTC)
- @Sanfranman59: I am currently working on the State Department project above, but will give this a look when done. Billboard is one of the most difficult sites because it is so frequently templated including templates embedded in the middle of URLs. You are right about other Billboards, I come across them during dead link repair. -- GreenC 21:28, 24 May 2019 (UTC)
- @Sanfranman59: Seems like the URLs work either way:
- The second URL redirects to the first. A bot might help in removing any
{{dead link}}and set|dead-url=nois that what you were thinking? -- GreenC 15:28, 30 May 2019 (UTC)
- @GreenC: Ahh ... I didn't pick up on that. Thanks for checking it. User:H3llBot added the dead link tags all the way back in October 2010, so billboard.com must not have set up the redirects until after that. If there's a way to do as you suggest, it would help those of us working on dead link repair to not have these false positive turning up. Thanks again. --sanfranman59 (talk) 18:06, 30 May 2019 (UTC)
Online Medieval and Classical Library
Since early 2018, http://omacl.org points to a payday loan provider. Texts formerly at http:/omacl.org/<rest of url> are now at http://mcllibrary.org/<rest of url>. Professor Quibble (talk) 15:08, 5 June 2019 (UTC)
charts.org.nz
As said over at Template talk:Single chart charts.org.nz is now dead. It can in all 20ish cases I've tested be changed to charts.nz to fix it. 6200 links according to Special:Linksearch. --Trialpears (talk) 12:45, 29 August 2019 (UTC)
Conversions: 5,315 URLs in 4,503 pages:
Trialpears,MrLinkinPark333,Muhandes: this is done. -- GreenC 16:13, 31 August 2019 (UTC)
- Wow! I'm impressed that you got them done already. --MrLinkinPark333 (talk) 21:25, 31 August 2019 (UTC)
Newspaper Archive
Hello. I came across Newspaper Archive links that have "access" in their domain name: access.newspaperarchive.com. Clicking on these links come up with an Authenication failed error (see Marriott's Great America (Maryland–Virginia) for example). If I remove the access part from the link from here, it properly links to the right citation here). There are over 200 links with https and over 100 with http. Thanks! --MrLinkinPark333 (talk) 18:46, 22 September 2019 (UTC)
proni.gov.uk
Web archive provider is defunct. Archives were moved to archive-it.org though some were lost in the move. See WP:WEBARCHIVES. Links. -- GreenC 15:56, 5 October 2019 (UTC)
collectionscanada.gc.ca
Web archive provider moved to bac-lac.gc.ca:8080 see WP:WEBARCHIVES. Links. -- GreenC 15:55, 5 October 2019 (UTC)
europarchive.org and collections.internetmemory.org
Web archive is defunct. They moved twice, first from europarchive.org to collections.internetmemory.org and then from collections.internetmemory.org to archive-it.org -- some were lost in the move. See WP:WEBARCHIVES. Links1, Links2. -- GreenC 15:55, 5 October 2019 (UTC)
Microsoft Mathematics
link at https://www.microsoft.com/en-us/p/microsoft-math/9wzdncrdtkn3 is dead and requires marking as dead, i also recommend checking other external links on the wikipedia entry for it being dead.
Amdcrash (talk) 15:22, 10 October 2019 (UTC)
- Not a good task for a bot. -- GreenC 12:51, 16 October 2019 (UTC)
cadial.hidra.hr to digured.hr/cadial
URL migration completed by GreenC
|
|---|
|
This may be small potatoes, but the Croatian government database known as CADIAL has moved from cadial.hidra.hr to digured.hr/cadial due to government restructring. This database is used as an easy respository of all Croatian government official publications, including all the laws. I do believe that the actual database is the same, so simple substitution of the urls may be sufficient, but I don't have the necessary technical knowledge to absolutely confirm this. Please consider having a look if conducting a proper url migration may be necessary. Melmann 18:05, 9 September 2019 (UTC)
|
LDS.org
Originally posted here.
The Church of Jesus Christ of Latter-Day Saints recently gave an announcement about the correct name of the church[1]. Because of this announcement, the church site has been changed from lds.org to ChurchofJesusChrist.org, and the newsroom from MormonNewsroom.com to Newsroom.ChurchofJesusChrist.org. Most wiki pages still have the old site linked. The only thing to be changed is the domain. The rest of the URLs are the same.
Thanks, The 2nd Red Guy (talk) 16:40, 23 April 2019 (UTC)
- but that link just redirects to the LDS.org version of the same page, so this change is just cosmetic rather than (currently) curing / preventing linkrot. Spike 'em (talk) 16:49, 23 April 2019 (UTC)
There are about 6,000 articles with lds.org -- as noted by Spike it looks like they have yet to make the switch themselves so we should wait until they are ready. There are a couple reasons to switch: redirects degrade over time either stop working entirely or redirect to a homepage creating soft-404s that are hard to recover from. The new domain may have content the old site doesn't, or different formatting. Adding the new URL triggers Wayback Machine to begin saving from the new URL ensuring contiguous backup coverage if the redirect ever stopped working. -- GreenC 17:35, 23 April 2019 (UTC)
Hey, GreenC, the change was made earlier last week, also Mormon.org is now ComeuntoChrist.org. -- The 2nd Red Guy (talk) 19:38, 9 June 2019 (UTC)
- @The 2nd Red Guy: - I missed your post from 29 days ago.. right at the moment I'm super busy with a different problem but hope within a week or two to have some clear time and will look into it. Thanks for the update and sorry for the belated reply. -- GreenC 20:45, 8 July 2019 (UTC)
Conversions list:
- http://lds.org --> https://churchofjesuschrist.org
- http://ldschurchtemples.com & org --> https://churchofjesuschristtemples.org
- http://mormontemples.org & com --> https://churchofjesuschristtemples.org
- http://mormonnewsroom.com & org --> https://newsroom.churchofjesuschrist.org
- http://ldschurchnews.org & com --> https://newsroom.churchofjesuschrist.org
- http://www.ldschurchnewsarchive.com --> https://www.thechurchnews.com
- http://mormon.org & com --> https://comeuntochrist.org
{kind=link}
- Templates:
-- GreenC 23:44, 16 July 2019 (UTC)
The 2nd Red Guy - after considerable effort and time, I'm done with the above project. Probably about 98% of the links have been moved, somewhere around 10,000 URLs. To complete the move, you or someone would still need to do three things, that need to be done manually:
- Check the External links search for each domain (org and com / and http and https ie. 4 checks for each domain). This is because some links the bot either could not parse in the page, or could not determine the destination. It's not so easy as changing the domain name, you will have to hunt down the URL at the remote site including using the LDS website search function. Always verify the new URL is working, do not simply search/replace domain names as that will break things more often than not.
- mormon.org & com --> comeuntochrist.org has to be done manually because there are too many false positives, there is not good redirect information. The list of articles that contain mormon.org & com are given above. Same thing, hunt down the page at the destination site by using the website search function.
- The LDS templates should be done manually. The list of templates are given above.
Any questions let me know, -- GreenC 15:56, 18 July 2019 (UTC)
Refs
References
- ^ an announcement about the correct name of the church Nelson, President Russell M. (7 October 2018). "The Correct Name of the Church - By President Russell M. Nelson". www.churchofjesuschrist.org. Retrieved 23 April 2019.
451 HTTP Error Link Rot Apocalypse
Many thousands of links are dead due to the website owners refusing to provide the privacy protections required by law and instead just killed the links outright, for EU visitors. Here is a list of sites where the links are suffering from link rot: https://data.verifiedjoseph.com/dataset/websites-not-available-eu-gdpr
To solve the problem of the massive 451 link rot apocalypse a bot fix would be best, to automatically replace the dead links with the Internet Archive archived links. I've started bug thread here to get the InternetArchiveBot to fix the issue: https://phabricator.wikimedia.org/T225765
-KristofferR (talk) 23:23, 13 June 2019 (UTC)
thebold.com broken redirects
Since early 2019, pages with URLs https://thebold.com/<rest of URL> are now at https://medium.com/@ReignFC/<rest of URL>. It would be great if a quick bot can fix these links! Mightytotems (talk) 13:10, 6 July 2019 (UTC)
- Mightytotems, I see 8 cases (3 https and 5 http). Can you do it manually? -- GreenC 13:43, 6 July 2019 (UTC)
- GreenC, most of them are in sources and refs (see, e.g., here). I manually fixed the ones on Reign FC but, with WP:Checklinks not working, it was more time than I can afford to spend on it now (one season page, for instance, has at least 30+ of these to fix). No worries if this is not possible now. Mightytotems (talk) 14:03, 6 July 2019 (UTC)
User:Mightytotems, Ok tried a different search method and now seeing in 29 articles:
I could probably quick script it and manually check and fix any mistakes. -- GreenC 14:44, 6 July 2019 (UTC) User:Mightytotems, this is done. If you find any more I might have missed let me know. -- GreenC 15:09, 6 July 2019 (UTC)
- GreenC, thank you so much! Mightytotems (talk) 18:22, 6 July 2019 (UTC)
- Manual check found similar issue exists for "thebold.net" as well, though cases are a lot fewer. If you can modify the script lightly and fix it that would be great! Mightytotems (talk) 18:35, 6 July 2019 (UTC)
- @Mightytotems:, done on 20 articles eg. 2017 Seattle Reign FC season. -- GreenC 17:44, 7 July 2019 (UTC)
- Thank you again! Mightytotems (talk) 18:37, 7 July 2019 (UTC)
- @Mightytotems:, done on 20 articles eg. 2017 Seattle Reign FC season. -- GreenC 17:44, 7 July 2019 (UTC)
Images of England conversion
- Discussion moved from WP:BOTREQ on July 26, 2019
As discussed in this TfD http://www.imagesofengland.org.uk will be closing down after the recent migration of all content to the National Heritage List for England. This will result in {{Images of England}} generating broken links when the site is retired in early August. To fix this problem it has been suggest that all instances of {{Images of England}} should be replace with {{National Heritage List for England}}, linking to the same content at its new destination . This will require updating of the number given to the template as IoE and NHLE use different ID systems, the mapping of which is recorded in a 386 thousand row CSV file which I have gotten from Historic England, the organisation behind NHLE. I will send it to anyone interested, preferably by email. I also want to add that there may be some items that were added after the CSV file was created that won't be in the mapping and would have to be dealt with manually. -- Trialpears 21:45, 12 July 2019 (UTC)
- Trialpears, I can automate conversion where possible (WP:URLREQ) as part of the solution. Send a wiki email and I'll respond with an address. -- GreenC 05:17, 16 July 2019 (UTC)
- GreenC I've sent a wiki email now. The actual things that should be replaced are as follows:
- Change {{Images of England}} to {{National Heritage List for England}} and change the old IoE ID in parameter 1 or num to the new NHLE ID. {{NHLE}} currently doesn't support using unnamed parameters aliases and don't have the ps alias for postscript, other than that they're completley compatible.
- Possibly change http://www.imagesofengland.org.uk/Details/Default.aspx?id=OLD_ID to https://historicengland.org.uk/listing/the-list/list-entry/NEW_ID I'm a bit hesitant since the website field would have to change as well in raw citations, but having a working link is always better then not having one.
- Thank you for offering to help with this task! -- Trialpears (talk) 09:19, 16 July 2019 (UTC)
- There could be problems with template expansion limit on the list pages - it may be time to revert the {{NHLE}} template to not use the wrapper invocation as I expect this adds to the expansion size. Keith D (talk) 10:16, 16 July 2019 (UTC)
- Thank you for offering to help with this task! -- Trialpears (talk) 09:19, 16 July 2019 (UTC)
- You will also have to change the second unnamed parameter in the {{IoE}} template to
|desc=in the {{NHLE}} template. Keith D (talk) 10:20, 16 July 2019 (UTC)
- You will also have to change the second unnamed parameter in the {{IoE}} template to
- The bot is coded. Ping when ready to run. -- GreenC 15:37, 19 July 2019 (UTC)
- @GreenC: The TfD has now closed as merge so I think it's time to run the bot. -- Trialpears (talk) 20:40, 26 July 2019 (UTC)
- @Trialpears:, discussion moved from WP:BOTREQ to WP:URLREQ as it is the bot doing the work and keeps a record of URL move/requests in the same place for other Wiki languages to track. -- GreenC 21:08, 26 July 2019 (UTC)
- @GreenC: The TfD has now closed as merge so I think it's time to run the bot. -- Trialpears (talk) 20:40, 26 July 2019 (UTC)
@Trialpears:, looks like some of the data in the CSV file is corrupt. There are duplicate entries. For example given the IoE number 32623, there are two NHLE numbers (csv rows):
- 32623: Historic England. "Details from listed building database ({{{num}}})". National Heritage List for England. Retrieved 27 July 2007.
So far it looks like the first entry in the CSV is right and the second wrong. Only a little concerning if the map may be wrong :) I'll keep doing spot checks and go slow. -- GreenC 22:09, 26 July 2019 (UTC)
- GreenC, That is concerning. Judging from the bot continuing editing it's fine anyway? Was ignoring duplicate entries enough to solve it? --Trialpears (talk) 15:53, 27 July 2019 (UTC)
- It seems to be the case the first entry is always right. There is another problem where IDs are missing in the CSV, in those cases the bot expands the template to
{{cite web}}with an archive URL, like in this diff: [3] But every one I check, the URL goes to a dead page (though the headers report 200). So these are soft-404s. What to do with them? I left them in the article in case someone wants to manually track down the correct page at the new site, or replace with a different ref. I can post a list of them if you want, around 100. -- GreenC 16:15, 27 July 2019 (UTC)- I'll fix those if it isn't more. It will be a lot easier to do before IoE goes down as well. --Trialpears (talk) 17:04, 27 July 2019 (UTC)
- It turns out to be 178 links. That would be great whatever you can. The list is User:GreenC/data/IoE. Feel free to edit the page or copy elsewhere. -- GreenC 17:25, 27 July 2019 (UTC)
- The Richard Chauncey article was using an NHLE number in an IoE template, and a few others had digits missing or in one case incorrect (there are probably more of these that are still valid but refer to other buildings). Of the remaining links, some contain IoE IDs that can still be found in NHLE, Stretton Aqueduct links to a news item on the site, Reedness links to a list entry that was removed but can be found via the archive URL, then there are all the list entries for buildings in Bath where the listings were updated and many given new IDs after IoE stopped updating and before the NHLE. Peter James (talk) 21:31, 28 July 2019 (UTC)
- It turns out to be 178 links. That would be great whatever you can. The list is User:GreenC/data/IoE. Feel free to edit the page or copy elsewhere. -- GreenC 17:25, 27 July 2019 (UTC)
- I'll fix those if it isn't more. It will be a lot easier to do before IoE goes down as well. --Trialpears (talk) 17:04, 27 July 2019 (UTC)
- It seems to be the case the first entry is always right. There is another problem where IDs are missing in the CSV, in those cases the bot expands the template to
- Many thanks for all the hard work on this conversion. I have only spotted one on my watchlist that has converted wrong IoE 232985 was converted to NHLE 1286623 (which does not exist) instead of 1264288. Keith D (talk) 22:32, 27 July 2019 (UTC)
- Thanks for the recognition, Keith D. These URL changes rarely go easy, they each have unique features and problems that require custom code. Verified IoE 232985 <-> NHLE 1286623 is the mapping they provided us so the bot did the right thing in that sense. It would be possible to check the target page exists, but I didn't think to do that and probably should have. Since they gave is the mappings I assumed it was accurate. -- GreenC 02:01, 28 July 2019 (UTC)
- It converted correctly, only NHLE 1286623 was removed as a duplicate (in this case, probably because there were originally separate lists for each district and it was in more than one). Unfortunately when IDs change or are removed they return "not found", not a redirect or explanation of where they can be found and as a result many IoE images haven't been transferred - it's likely that more of these could be found by comparing the CSV file with an updated list. The second entry for 32623 is a scheduled monument; NHLE numbers for listed buildings start at 1021466 and anything below that is from another database. Peter James (talk) 21:31, 28 July 2019 (UTC)
- Hi User:Peter James it sounds like you know something more about this on the NHLE side maybe you can help. The links that did not convert are listed here, probably 1000-1500 in mainspace. If you would like a list of the URLs I can provide it. If you have access to a more accurate mapping file, I can re-run the bot on these ~1500 pages to convert them. -- GreenC 02:03, 29 July 2019 (UTC)
- Most of what I know is from Wikidata, where items such as d:Q4950955 have a different number for each heritage status and qualifiers are used. By "list of the URLs" do you mean the converted or the CSV that has been mentioned?. If you could provide the CSV, that would help in maintaining links but the converted URLs could also be useful. The remaining links that could be updated either have "pid=2&" or something similar in the URL (as in Union Mill, or an error in the URL, or are for buildings in Bath. I've started looking at these and some such as Bathwick Hill, seem to be replaced by new IDs but others, such the two in Grosvenor Place, Bath, are split and each would need two references. Peter James (talk) 12:59, 4 August 2019 (UTC)
- Peter James, I fixed the cases with "?pid=" about 200 links (example). I'll send you a wiki email with the CSV, and a log file of the conversions (templates and URLs). -- GreenC 14:34, 4 August 2019 (UTC)
- Thanks, I've received it. I've been comparing the URLs with Wikidata which has data from 2016 and found a few dead links and have been updating the articles. The relevant List Entry UIDs are in the range 1021466-1396602; the CSV also contains some de-listed buildings (1396673-1399699), which are always "not found" on the Historic England website, and higher numbers that are usually duplicates and probably another type of item with the same Legacy UID as a listed building, as this is the case with the scheduled monuments (possibly similar to the UID at Norfolk Heritage Explorer). I've also found another type of URL in need of updating - http://www.heritagegateway.org.uk/Gateway/Results_Single.aspx?uid=204876&resourceID=5 links to the Heritage Gateway home page; the page is now at http://www.heritagegateway.org.uk/Gateway/Results_Single.aspx?uid=1081012&resourceID=5 - in these URLs, resourceID=5 is for listed buildings; other values, probably including some starting with 5, are used for other sources. Peter James (talk) 23:26, 6 August 2019 (UTC)
- Peter James, I fixed the cases with "?pid=" about 200 links (example). I'll send you a wiki email with the CSV, and a log file of the conversions (templates and URLs). -- GreenC 14:34, 4 August 2019 (UTC)
- Most of what I know is from Wikidata, where items such as d:Q4950955 have a different number for each heritage status and qualifiers are used. By "list of the URLs" do you mean the converted or the CSV that has been mentioned?. If you could provide the CSV, that would help in maintaining links but the converted URLs could also be useful. The remaining links that could be updated either have "pid=2&" or something similar in the URL (as in Union Mill, or an error in the URL, or are for buildings in Bath. I've started looking at these and some such as Bathwick Hill, seem to be replaced by new IDs but others, such the two in Grosvenor Place, Bath, are split and each would need two references. Peter James (talk) 12:59, 4 August 2019 (UTC)
- Hi User:Peter James it sounds like you know something more about this on the NHLE side maybe you can help. The links that did not convert are listed here, probably 1000-1500 in mainspace. If you would like a list of the URLs I can provide it. If you have access to a more accurate mapping file, I can re-run the bot on these ~1500 pages to convert them. -- GreenC 02:03, 29 July 2019 (UTC)
- It converted correctly, only NHLE 1286623 was removed as a duplicate (in this case, probably because there were originally separate lists for each district and it was in more than one). Unfortunately when IDs change or are removed they return "not found", not a redirect or explanation of where they can be found and as a result many IoE images haven't been transferred - it's likely that more of these could be found by comparing the CSV file with an updated list. The second entry for 32623 is a scheduled monument; NHLE numbers for listed buildings start at 1021466 and anything below that is from another database. Peter James (talk) 21:31, 28 July 2019 (UTC)
- Thanks for the recognition, Keith D. These URL changes rarely go easy, they each have unique features and problems that require custom code. Verified IoE 232985 <-> NHLE 1286623 is the mapping they provided us so the bot did the right thing in that sense. It would be possible to check the target page exists, but I didn't think to do that and probably should have. Since they gave is the mappings I assumed it was accurate. -- GreenC 02:01, 28 July 2019 (UTC)
Peter James, somehow I missed the above re: heritagegateway.org.uk .. quite a few links. Will take a look. -- GreenC 17:28, 30 August 2019 (UTC)
- There are done, 539 URLs in 235 articles. Example. -- GreenC 22:00, 31 August 2019 (UTC)
Statistics
- Conversions of bare URLs: 5,230 URLs in 2,438 pages:
- Conversions of bare URLs in Commons: 2,492 URLs in 2,429 pages:
{kind=link}
{kind=link}
- IABot database: imagesofengland.org.uk is "Blacklisted"
NSSDC
The NASA Space Science Data Coordinated Archive (NSSDCA) URL has moved. I propose we point the dead links we have to the new location, as in this edit.
- https://nssdc.gsfc.nasa.gov/nmc/masterCatalog.do?sc=1970-029C (old form)
- https://nssdc.gsfc.nasa.gov/nmc/spacecraft/display.action?id=1970-029C (new form)
The query string identifies the spacecraft (it is the COSPAR ID), so in this case 1970-029C is the unique identifier.
Let me know if additional information is required, thanks. Kees08 (Talk) 15:29, 20 August 2019 (UTC)
- @Kees08: found two other forms that are 404:
- and
- There are two more forms that still work because of redirects:
- I wondering, if 3 forms don't work and 2 forms do (via redirect), the 2 redirect forms may be unreliable in the future and now might be a good time to change them, also, to prevent future link rot and register the URLs in the Wayback database. Do you agree? -- GreenC 19:28, 20 August 2019 (UTC)
- That makes sense, I have fixed a lot of these while working through articles, I was wondering why there were not many of the form I specified. I agree on all counts. Kees08 (Talk) 20:08, 20 August 2019 (UTC)
- @Kees08: - The conversion is mostly done (stats below). This list shows a dozen or two remain in mainspace (example: in 500 view, line #106 for Mars 2M No.521). This is because they were converted to archive URLs, or it can't determine because the new URL isn't working (example). They need manual intervention to find a new URL. I'm going to pass on it, but letting you know in case you want to research these. -- GreenC 15:17, 21 August 2019 (UTC)
- Perfect, thank you. I will take care of the remainder manually. Kees08 (Talk) 16:47, 21 August 2019 (UTC)
- Hey GreenC, was looking at another article and I saw one link that was broke as a results of this (here). Looks like it might have to do with the experiment links? I can look at it more tomorrow. Kees08 (Talk) 07:51, 31 August 2019 (UTC)
- User:Kees08, Hmm that is a soft-404 - the bot checked for status 200 (which this is) but not for text in the page. Related the "/experiment/" links. The correct link is https://nssdc.gsfc.nasa.gov/nmc/experiment/display.action?id=1969-099C-03 ("/spacecraft/" is changed to "/experiment/"). I keep logs so know which links were incorrectly changed. -- GreenC 14:44, 31 August 2019 (UTC)
- Hey GreenC, was looking at another article and I saw one link that was broke as a results of this (here). Looks like it might have to do with the experiment links? I can look at it more tomorrow. Kees08 (Talk) 07:51, 31 August 2019 (UTC)
- Perfect, thank you. I will take care of the remainder manually. Kees08 (Talk) 16:47, 21 August 2019 (UTC)
- These are fixed, 225 URLs in 84 articles. Example. -- GreenC 17:02, 31 August 2019 (UTC)
Statistics
chartarchive.org and chartstats.com (again)
(section moved from WP:BOTREQ)
As MrLinkinPark333 pointed out, there are still about 1600 mentions of chartarchive.org and chartstats.com around Wikipedia. Going over a few, I noticed they are mainly leftovers from a run of Cyberbot II back in 2013 which changed to url field, but left the |publisher= field as is (pinging Cyberpower678). This is not only an eyesore, it is also a bit misleading regarding the publisher. I would suggest a bot run to fix it.
Secondly, all those links are not really working since https://www.theofficialcharts.com/ no longer exists. It used to redirect to http://www.officialcharts.com/ but this redirect no longer works. If this was the only problem, I would ask at Wikipedia:Link rot/URL change requests, but the search structure has also changed. It seems like a call to https://www.theofficialcharts.com/search-results-album/_/ALBUMNAME#album will now need to go to https://www.officialcharts.com/search/albums/ALBUMNAME/ and ones that went to http://www.theofficialcharts.com/search-results-album/_/SINGLENAME#single now going to https://www.officialcharts.com/search/singles/SINGLENAME/
A single run that would fix both would be nice, but I think the first in itself is worth fixing. --Muhandes (talk) 12:28, 30 August 2019 (UTC)
- Well these sorts of complex URL conversions are what Wikipedia:Link rot/URL change requests was designed to make requests for. So long as it is possible to make the conversion, if enough data is available. -- GreenC 13:50, 30 August 2019 (UTC)
- @GreenC: First, I'm not sure these are the only two types of URLs used, Cyberpower678 should have more details. Second, does Wikipedia:Link rot/URL change requests also cover the
|publisher=field change? --Muhandes (talk) 14:19, 30 August 2019 (UTC)- Yes configured for
|publisher=,|work=and other aliases. If it sees the old domain name in those fields it changes to the new (there is some manual oversight to make sure it does what expected). Open a request at WP:URLREQ or copy/move this thread there so we have a record of change requests. -- GreenC 15:02, 30 August 2019 (UTC)- Thread moved here. Re-pinging @Cyberpower678 and MrLinkinPark333: to notify new place for discussion. --Muhandes (talk) 16:36, 30 August 2019 (UTC)
- I did not know this section existed! Added to my watchlist. Thanks! --MrLinkinPark333 (talk) 16:40, 30 August 2019 (UTC)
- Muhandes, This is a task I wrote 6 years ago and have no details remaining in my head about it. Not able to help here. Sorry. —CYBERPOWER (Chat) 18:01, 30 August 2019 (UTC)
- Thread moved here. Re-pinging @Cyberpower678 and MrLinkinPark333: to notify new place for discussion. --Muhandes (talk) 16:36, 30 August 2019 (UTC)
- Yes configured for
- @GreenC: First, I'm not sure these are the only two types of URLs used, Cyberpower678 should have more details. Second, does Wikipedia:Link rot/URL change requests also cover the
- Hey I will do this, but need to need to finish a couple pending projects before starting a new one, hopefully it won't more than a few weeks. This one looks like it might be a bit complicated so want to give it the time it will need. -- GreenC 13:29, 1 September 2019 (UTC)
Muhandes, theofficialcharts.com/search-results-album and chartarchive.org are mostly done, the few left could be done manually. chartstats.com has a lot of URLs and it is unknown how to convert (if they can even be). I can flag this domain dead and add archive URLs, or if you know how they convert. -- GreenC 03:37, 12 September 2019 (UTC)
- Looking at the old CyberbotII BRFA, chartstats.com was an unlicensed/pirate user of data scraped from OCC, so OCC had them redirect chartstats.com links to OCC. But since then the domain chartstats.com has expired and we lost the redirects and thus have no idea what the URLs should point to at OCC. Options are add archive URLs for chartstats.com which would in-effect restore the unlicensed/pirate content. If we don't do that, all these cites should be deleted entirely otherwise other bots and people will add archive URLs. Personally I don't care, adding archive URLs would be the easiest solution from a bot op perspective. Deleting 1500 citations isn't easy because of the free-form types, combined refs, tables, Harvard etc. -- GreenC 03:58, 12 September 2019 (UTC)
- @GreenC: This effort could have been much easily done when chartstats was alive, but we can still salvage some of it, if you are willing to do a two-step translation. First translate from chartstats to chartarchive then translate to officialcharts.
- Songs: Breathe (British band) uses http://www.chartstats.com/songinfo.php?id=13140
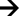 http://chartarchive.org/r/13140. Looking at this we get
http://chartarchive.org/r/13140. Looking at this we get Title: Wicked Ways https://www.officialcharts.com/search/singles/wicked%20ways/ - Albums: Sadly doesn't work. Want (3OH!3 album) uses http://www.chartstats.com/albuminfo.php?id=14592 http://chartarchive.org/r/14592 is wrong, the right one is http://chartarchive.org/r/48807. The only solution I can think of is to direct at https://www.officialcharts.com and categorize so they can be manually fixed.
- Artist: No solution. Terry Hall discography uses http://www.chartstats.com/artistinfo.php?id=3246 Should be translated to http://chartarchive.org/a/terry+hall and then https://www.officialcharts.com/artist/28312/terry-hall/ but the first link is broken. Maybe redirect to https://www.officialcharts.com/artists/ and categorize so they can be manually fixed?
- Release: This works, but needs to peak at what the release is.
- Single: Keith Hale uses http://www.chartstats.com/release.php?release=9054 http://chartarchive.org/r/9054
Title: Four From Toyah (EP)Type: Single https://www.officialcharts.com/search/singles/four%20from%20toyah%20(ep)/ - Album: Keith Hale uses http://www.chartstats.com/release.php?release=39614 http://chartarchive.org/r/39614
AnthemType: Album https://www.officialcharts.com/search/albums/anthem
- Single: Keith Hale uses http://www.chartstats.com/release.php?release=9054
- Songs: Breathe (British band) uses http://www.chartstats.com/songinfo.php?id=13140
- Hopefully this is of some use. --Muhandes (talk) 11:04, 12 September 2019 (UTC)
- Muhandes, very useful. Should be done with "release.php" and "songinfo.php" by tomorrow. That completes about 40% of the links. The remaining 60% are "No solution". I agree with your idea to convert them to https://www.officialcharts.com/archive/official-albums-chart/ and https://www.officialcharts.com/artists/ .. prefer not to add a hidden tracking category directly into mainspace (vs. in template code) for a couple reasons, but could create a page listing all the articles with this problem. This page could also describe the history and be linked from the edit summary. Only question is where to put the page and name. -- GreenC 05:56, 13 September 2019 (UTC)
- @GreenC: I'd think these output files are pretty common but I guess I'm wrong. Wikipedia:Link rot/URL change requests/chartarchive.org and chartstats.com will work for me, but you can also put it in my namespace if you wish, I may move it later as a sub-page of Wikipedia:WikiProject Albums/to do if people there would be willing to give it a try.--Muhandes (talk) 10:24, 13 September 2019 (UTC)
- Muhandes, very useful. Should be done with "release.php" and "songinfo.php" by tomorrow. That completes about 40% of the links. The remaining 60% are "No solution". I agree with your idea to convert them to https://www.officialcharts.com/archive/official-albums-chart/ and https://www.officialcharts.com/artists/ .. prefer not to add a hidden tracking category directly into mainspace (vs. in template code) for a couple reasons, but could create a page listing all the articles with this problem. This page could also describe the history and be linked from the edit summary. Only question is where to put the page and name. -- GreenC 05:56, 13 September 2019 (UTC)
- @GreenC: This effort could have been much easily done when chartstats was alive, but we can still salvage some of it, if you are willing to do a two-step translation. First translate from chartstats to chartarchive then translate to officialcharts.
- Needed to post lists in a prior case so I started a Wikipedia:Link rot/cases page that links to Wikipedia:Link rot/cases/chartarchive.org and chartstats.com. -- GreenC 15:55, 13 September 2019 (UTC)
- Muhandes,
- chartstats.com is no more as of this post. It will get re-added by reverts, moves from Draft/User, other wikis, copy-pastes etc so worth revisiting in the future.
- Per discussion above the case page is updated with the generic officialcharts.com URLs that need community help to fill in. There are 2,232
- There are 110 chartarchive.org that need community help to convert.
- There are are still around 2,726 theofficialcharts.com URLs. They are mostly archived but it would be good to convert them to the live site if there were some formula(s) similar to the /search-results-album recipe.
-- GreenC 16:07, 14 September 2019 (UTC) @Muhandes: -- GreenC 16:07, 14 September 2019 (UTC)
- Statistics
- URL conversion from theofficialcharts.com/search-results-album: 506 URLs in 377 articles
- Conversion from chartstats.com to specific officialcharts.com: 2,259 URLs in 2,124 articles
- Conversion from chartstats.com to generic officialcharts.com: 2,232 URLs in 2,089 articles
- Template conversion from charstats.com to generic officialcharts.com:
{{UKChartHits}}
- @GreenC: Thanks for all the work. I will review what we have left and see if I can find more that can be automated. --Muhandes (talk) 17:48, 14 September 2019 (UTC)
- Sothe ones in the UKChartHits template should be converted to a more specific citation correct @GreenC:? Luckily, there's not much to switch out if that's the case. --MrLinkinPark333 (talk) 19:10, 16 September 2019 (UTC)
- Yes, though IMO the templates should be swapped for full URLs then delete the template. The template prevented the bot from doing its job and will again in the future if/when those URLs go dead. Templates are an all-or-nothing approach and don't account that some URLs work and some don't (it was like 50/50). Or that bots are not programmed to deal with them. Future-proof going with standard
{{cite web}}rather then custom/proprietary templates. -- GreenC 21:42, 16 September 2019 (UTC)- @GreenC: Links to UKChartHits have been replaced. THe only instances left are ones on userpages/talk pages. I can work on the chartarchive.org ones as it's smaller to go through. --MrLinkinPark333 (talk) 23:51, 16 September 2019 (UTC)
- Excellent. It is nominated for deletion at TfD. -- GreenC 23:31, 17 September 2019 (UTC)
- @GreenC: Links to UKChartHits have been replaced. THe only instances left are ones on userpages/talk pages. I can work on the chartarchive.org ones as it's smaller to go through. --MrLinkinPark333 (talk) 23:51, 16 September 2019 (UTC)
- Yes, though IMO the templates should be swapped for full URLs then delete the template. The template prevented the bot from doing its job and will again in the future if/when those URLs go dead. Templates are an all-or-nothing approach and don't account that some URLs work and some don't (it was like 50/50). Or that bots are not programmed to deal with them. Future-proof going with standard
- Sothe ones in the UKChartHits template should be converted to a more specific citation correct @GreenC:? Luckily, there's not much to switch out if that's the case. --MrLinkinPark333 (talk) 19:10, 16 September 2019 (UTC)
- @GreenC: Thanks for all the work. I will review what we have left and see if I can find more that can be automated. --Muhandes (talk) 17:48, 14 September 2019 (UTC)
Unbreak a batch of PDF links
The North Carolina Department of Natural and Cultural Resources redid its website some time back, breaking a lot of links (maybe about 3000?) from Wikipedia in the process. The filenames are identical as far as I've seen (they reflect the department's internal numbering system); only the filepaths are different. Example:
- http://www.hpo.ncdcr.gov/nr/MK0090.pdf — old URL format #1
- https://www.ncdcr.gov/state-historic-preservation-office/nr/MK1809.pdf — old URL format #2
- https://files.nc.gov/ncdcr/nr/MK0090.pdf — correct form of URL #1
- https://files.nc.gov/ncdcr/nr/MK1809.pdf — correct form of URL #2
Could someone run a bot to replace the old syntax with the new? Presumably the bot needs to find each occurrence of the old syntax, check the corresponding new URL to ensure that there's a PDF file with that name, replace old with new if the new link works, and log the items whose new-syntax links don't work. Also, by this time, some of the URLs have probably been tagged with {{dead link}}, so if the bot replaces a link, it should remove any associated appearances of this template. Nyttend (talk) 23:54, 8 September 2019 (UTC)
Extended content
|
|---|
|
PS, maybe you could replace the link with a template, comparable to {{OHC NRHP}}? This would simplify any future changes, but the problem is that someone frequently embedded these old URLs in citation templates, and I don't know if nested templates will work properly. Nyttend (talk) 02:11, 10 September 2019 (UTC)
|
Leaving aside my abortive template idea...is my original replace-old-with-new request practical? I know it's not urgent, and I'm not treating it thus; I'm just concerned that this discussion will die out if I don't ask soon. Nyttend (talk) 02:50, 13 September 2019 (UTC)
Nyttend, oh yes no problem. These projects take some some time and effort. I'm currently working in the chartarchive.org section above which is pretty complex. Then cadial.hidra.hr which looks easier, and then here. Plus other projects not on this page.. sigh. -- GreenC 05:08, 13 September 2019 (UTC)
- Thanks! Just wanted to make sure we got back to the original question :-) WP:VOLUNTEER; I'm happy to wait until it's a convenient time for you. Nyttend (talk) 11:00, 13 September 2019 (UTC)
Hi Nyttend,
- The bot converted
www.hpo.ncdcr.gov/nr/URLs. The vast majority converted successfully but a few don't exist at the new site. Those were either archived Example, or if no archive exists left alone w/out a{{dead link}}(in Pegram House). Some had preexisting archives removed Example. - The remaining links recommend yourself and/or community attempt a repair by searching the new site for the intended page. All of the
www.hpo.ncdcr.gov/nr/links have already been checked by bot so you can probably skip those. The bot also only processes mainspace (and File:) it skips Projects, User:, Talk: etc.. - Once you determine everything remaining for this domain is dead or can't be saved, for each the bot will add a
{{dead link}}or archive it, if it exists (in mainspace). And also update the domain to dead in IABot.
Ping when ready to dead-ify the domain, regards. -- GreenC 14:20, 15 September 2019 (UTC)
@Nyttend: -- GreenC 14:43, 15 September 2019 (UTC)
- As you likely saw, many of the remaining links are general pages, not individual PDFs, so the solution is not a simple link replacement. For the ones with links to specific PDFs that couldn't be replaced, I suspect the solution is one-by-one work by a human, as you said, so I don't envision more bot work being needed. Just one question: did you do anything with URLs of the format https://www.ncdcr.gov/state-historic-preservation-office/nr/MK1809.pdf? Nyttend (talk) 22:05, 15 September 2019 (UTC)
- They are dead links so either need to be fixed, or archive URL added or
{{dead link}}tagged. A bot can do the last two. Re these links I don't see the "/nr/" format. Is there another way to convert these? -- GreenC 23:27, 15 September 2019 (UTC)
- They are dead links so either need to be fixed, or archive URL added or
BBC YourPaintings -> ArtUK
(section moved from WP:BOTREQ)
The BBC no longer host the "YourPaintings" project; some years ago, it became independent, as "ArtUK".
We still have a number of links to the former, often in citations. These need to be updated, as in this diff, please.
Note that the first URL does not follow the standard pattern, so each URL need to be checked for a 404 response bfore the change is made.
Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 19:35, 24 February 2019 (UTC)
- Andy Mabbett, the BBC URL automatically redirects. Example. Thus it would be easy to determine the new URL by looking at the page header redirect URL. The question is, do we make the change if the URL is otherwise working? Often we have not, when redirects occur within the same organization. But where it redirects across organizations, maybe there is a reason? -- GreenC 17:55, 28 February 2019 (UTC)
Andy Mabbett, after a closer look it appears the links are a mix of dead or working redirect. I will take this up using WP:WAYBACKMEDIC. It will require detecting dead status and either marking dead, or adding an archive URL if available .. or it not dead, then move the URL to the new redirect in the header. -- GreenC 17:01, 27 March 2019 (UTC)
@Pigsonthewing: - this is done. The BBC links were checked for 404 status, archive URLs searched for and added (or a {{dead link}}. If not 404, the redirect found and converted to artuk, and for any CS1|2 templates the |publisher= and/or |work= changed to Art UK and mention of "BBC" removed. Example. -- GreenC 21:07, 28 March 2019 (UTC)
- @GreenC: Thank you. Are you by any chance able to make the same changes on Commons? Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 21:52, 28 March 2019 (UTC)
- @Pigsonthewing: good question! It may be easy, or not. Worth a try. Can you submit a request at [4]. I do not have perms yet and need to get approved for Commons, your request makes it easier. -- GreenC 00:08, 29 March 2019 (UTC)
- Thank you; done: c:Commons:Bots/Work requests#BBC YourPaintings -> ArtUK. Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 09:49, 29 March 2019 (UTC)
- @Pigsonthewing: good question! It may be easy, or not. Worth a try. Can you submit a request at [4]. I do not have perms yet and need to get approved for Commons, your request makes it easier. -- GreenC 00:08, 29 March 2019 (UTC)
@Pigsonthewing:, Commons is done with over 2,000 links converted. The template {{BBCYourPaintings}} is also eliminated. There are still some BBC links transcluded from Wikidata. In the process I found new ways to discover Art UK URLs and re-processed Enwiki and converted most of the remaining BBC links (about 800 links). There are still a few that require manual lookups at the Art UK site, or simply don't exist there. -- GreenC 22:01, 2 May 2019 (UTC)
- @GreenC: That's great, thank you. How abut running your bot on Wikidata? Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits 08:39, 3 May 2019 (UTC)
- @Pigsonthewing: Ah it never ends. This is new also. query request. See what happens. -- 14:25, 3 May 2019 (UTC)
- @Pigsonthewing:, the situation at Wikidata is sort of done as you can see from the thread, thanks to MisterSynergy. But the old BBC links are not removed and thus still display at Commons (along with the new ArtUK links). It is pretty complicated at Wikidata. -- GreenC 16:07, 14 May 2019 (UTC)
US State Department reports
Following a reorganization of the State Department website, links to annual reports such as the International Religious Freedom Report are broken. Unfortunately, the pattern-recognition task for detecting and fixing these links is complicated: The old URLs include a variety of different opaque strings of letters and numbers, whereas the new targets vary depending on the year and report (example diff). Reports for years prior to 2016 are stored at a different archive site and have a different link structure (eg: [5]), and reports prior to 2009 have yet another format (eg [6]). I haven't looked at any citations to the site other than the religious freedom reports, but I would assume that there exist some other citations that have been similarly affected. signed, Rosguill talk 19:07, 20 May 2019 (UTC)
- Investigating.. -- GreenC 20:28, 20 May 2019 (UTC)
- There are 14,241 URLs in 7,118 articles (mainspace)... I think it can be straightforward (famous last words): check if the https://2009-2017.state.gov/... version exists, and if not treat it as a dead link and add an archive URL or a
|dead link=template (most will be available as archive). It will also verify the URL isn't live to avoid archiving live links such as those added recently. There are some in the gap between 2017 and whenever the new URL format came into existence, like this one the bot has no way to figure out, there is no header redirect info - those would be archived which is something anyway. It seems like most of them will be available through 2009-2017.state.gov -- Assuming this method is reasonable my bot can be configured for it. -- GreenC 22:42, 20 May 2019 (UTC) - Example diff. -- GreenC 17:48, 21 May 2019 (UTC)
- Also found https://1997-2001.state.gov/ and https://2001-2009.state.gov/ -- GreenC 15:03, 22 May 2019 (UTC)
- Found
{{StateDept}},{{US DOS}}and{{Overseas Security Advisory Council}}-- GreenC 14:54, 23 May 2019 (UTC)
@Rosguill: - project is completed. And also on Commons. I could use help identifying certain types of URLs that are soft-404 like the /biog/ URLs that successfully redirect but not to where it should go (here). If you see a pattern of others like /biog/ let me know, where they redirect to a home page rather then the final destination page. -- GreenC 04:05, 30 May 2019 (UTC)
- GreenC, thanks so much! I haven't come across any of the soft 404s but I'll let you know if I do. signed, Rosguill talk 04:56, 30 May 2019 (UTC)