
Wikipedia talk:Wikipedia Signpost/Single/2017-06-23
Comments
The following is an automatically-generated compilation of all talk pages for the Signpost issue dated 2017-06-23. For general Signpost discussion, see Wikipedia talk:Signpost.
Featured content: Will there ever be a break? The slew of featured content continues (842 bytes · 💬)
Great job enwiki! --Hume42 (talk) 07:36, 23 June 2017 (UTC)
- I expected to see a bit of commentary as to why this is. Particularly in the same Signpost where we have seen no new RfAs... are more people switching from administrative work to content creation? Or are there other factors at play? The headline almost sounds negative... "will we ever get a break from this *slew* of unwanted FAs
 . Joking aside, it sounds like great news, anyway. IMHO increasing the quality of our articles should be the absolute number one priority. — Amakuru (talk) 09:27, 23 June 2017 (UTC)
. Joking aside, it sounds like great news, anyway. IMHO increasing the quality of our articles should be the absolute number one priority. — Amakuru (talk) 09:27, 23 June 2017 (UTC)
In the media: Kalanick's nipples; Episode #138 of Drama on the Hill (5,562 bytes · 💬)
- Just as a note, not a fan of this popular style. Takes me too much time to interpret what is truly being stated. Innuendo is fun, but it can also be distracting. Especially if your English isn't top notch, that can be a problem. —TheDJ (talk • contribs) 09:22, 23 June 2017 (UTC)
- Yeah, I’m not a regular contributor, just helping out since there was a shortage. Sometimes we need innuendos and sometimes we don’t. Since this issue covered multiple months, I thought it would be nice to cover some topics with some wit. It might not have hit home, but I is better than nothing in my opinion. Feel free to write next issue though ;) (t) Josve05a (c) 10:52, 23 June 2017 (UTC)
It looks like the trolls at Motherboard have just doubled down on this. Sometime after their issue came out, an editor User:Czar took them up on their suggestion and replaced the contested photo. At which point Motherboard published an update that pretty much accuses him of a serious policy violation: "I just noticed that someone updated Travis Kalanick's Wikipage photo on June 11, 2017. Wikipedia user Czar, a seasoned editor and the person behind the change, cited "much better color in more recent photo" as the reason for their edit. It's unclear whether Czar works for, or is affiliated with, Uber. No mention was made of the nipples." Such is the just reward of going along with a PC crusade. To be sure, his user page says he accepts payments on Patreon, but "not for advocacy". At this point though, someone is going to have to ask him about this and make a decision, if only to make Motherboard take back their accusation, which seems awfully loose-cannon to be putting in print based on anything they've told us. Wnt (talk) 16:51, 23 June 2017 (UTC)
- Thanks—I didn't know about this, but are we looking at the same article? I see clickbait and bad journalism (no effort to contact me), not a "serious" allegation nor "doubling down", and that's as if the prior photo should have received any press at all
 czar 17:16, 23 June 2017 (UTC)
czar 17:16, 23 June 2017 (UTC) - Wow Motherboard is such an immature website. The fact Vice recently got an $450 million investment is painful to think about. GamerPro64 06:59, 24 June 2017 (UTC)
Meanwhile, of course, the Motherboard article has made this specific photo notable, making it even more of a no-brainer to put back in. :) I mean, there's no Wikipedia policy against a businessman looking good, or being seen at all outside those ridiculous Croatian cravats they have all made each other wear in recent times. Someday, someone will start a company that cares more about whether its administrators can do a good job than that they are fashion conformists ... Wnt (talk) 16:51, 23 June 2017 (UTC)
- Thanks for the mention of the The Times of Israel interviewing me regarding my Signpost article on Banc De Binary's paid editing and scamming. I would never suggest though that the Signpost is not "real news". It's a case of two different audiences. I felt honored to be able to present my research into Banc De Binary's editing here on Signpost where most readers understand the technicalities and wouldn't need the concept of "sockpuppet" explained. Getting feedback from our readers is invaluable.
- On the other hand, Israel is (soon to be was) the center of the binary options industry and having the opportunity to explain the situation to a general audience there was irresistible. The days are long-gone when we can sweep under the rug news that paid editors are scamming our readers.
- BTW, last week the Israeli cabinet passed the bill outlawing any binary options trading in or from Israel. Now just 3 successful readings in the Knesset and the bill becomes law. Smallbones(smalltalk) 17:55, 23 June 2017 (UTC)
::@Smallbones: I looked twice, and I can't see anything in the small items above that I can link to this. I even looked back at the Motherboard article (which now notes that User:Czar emailed them he was not affiliated with Uber, I should add) Could you explain, or is it possible you put this comment in the wrong place? Wnt (talk) 12:08, 24 June 2017 (UTC) Alright, I'm either going blind... or dumb. It was right there the whole time, and I missed it twice. Wnt (talk) 12:13, 24 June 2017 (UTC)
News and notes: Departments reorganized at Wikimedia Foundation, and a month without new RfAs (so far) (6,793 bytes · 💬)
- Wikipedia:List of administrators states 1262 admins (544 active, changes in Wikipedia talk:List of administrators). User:NoSeptember/Admin_stats lists 1463 in 2012 (latest date).
Extrapolating a linear loss at last five year rate gives (which doesn't take into account the current zero new admins rate):annual loss at (1463-1262)/5 = 40.2 admin/yearno admins in (1262/40.2) = 31 years, the year 2048
active annual loss at (744-529)/5 = 43 active/yearno active admins in (529/43) = 12 years, the year 2029
- Is "Departments reorganized at Wikimedia Foundation, and a month without new RfAs (so far)" meant to be "wikt:rearrange the deck chairs on the Titanic"? Widefox; talk 12:29, 23 June 2017 (UTC)
- You can't use a linear extrapolation. The number of active administrators is proportional to a Poisson point process and is a subset of active editors, which have stabilized over the past five years. 153.120.214.254 (talk) 10:50, 24 June 2017 (UTC)
- Linear is simplistic, what fits better? The annual losses of active admins since 2008 are: 42, 86, 88, 33, 81, 30, 50, 1, 53 (a mean of 51.5). A simple linear regression of active totals since 2008: r2=0.96, standard error = 32, 50 loss a year., extrapolation to 0 takes 9 years, the year 2026. An exponential decay model visually fits (unlike linear), and r2=0.98, the trend halving the active admins per decade, henceforth "active admin attrition (AAA) rate" (so 1000 ten years ago, 500 now, predicts 250 in 2027).Widefox; talk 09:59, 26 June 2017 (UTC)
- Here's a graph with better analysis (exponential regression fits only from mid 2011, total has r2=0.989 but a linear is similar) predicts less active admins than semi-active in a year from now, and total admin numbers 50% down from the peak by 2027:
- Linear is simplistic, what fits better? The annual losses of active admins since 2008 are: 42, 86, 88, 33, 81, 30, 50, 1, 53 (a mean of 51.5). A simple linear regression of active totals since 2008: r2=0.96, standard error = 32, 50 loss a year., extrapolation to 0 takes 9 years, the year 2026. An exponential decay model visually fits (unlike linear), and r2=0.98, the trend halving the active admins per decade, henceforth "active admin attrition (AAA) rate" (so 1000 ten years ago, 500 now, predicts 250 in 2027).Widefox; talk 09:59, 26 June 2017 (UTC)
- You can't use a linear extrapolation. The number of active administrators is proportional to a Poisson point process and is a subset of active editors, which have stabilized over the past five years. 153.120.214.254 (talk) 10:50, 24 June 2017 (UTC)
-
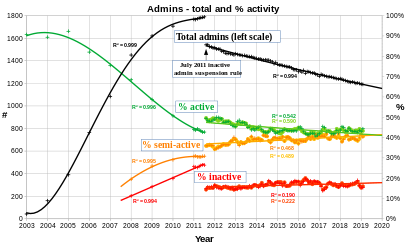 User:Widefox/editors English Wikipedia administrator numbers 2003-2019, total number (and % from peak), % active, % semi-active, % inactive
User:Widefox/editors English Wikipedia administrator numbers 2003-2019, total number (and % from peak), % active, % semi-active, % inactive -
 User:Widefox/editors English Wikipedia administrator numbers 2011-2019 (ditto legend)
User:Widefox/editors English Wikipedia administrator numbers 2011-2019 (ditto legend) -
 User:Widefox/editors English Wikipedia administrator numbers 2011-2029 (ditto legend)
User:Widefox/editors English Wikipedia administrator numbers 2011-2029 (ditto legend)



Widefox; talk 21:37, 30 June 2017 (UTC)
- What are "audience verticals"? Not all of us use such jargon. Thanks. Julietdeltalima (talk) 19:29, 23 June 2017 (UTC)
- Vertical market probably, and yes, the announcement is very heavy on Silicon Valley biz jargon. - Bri (talk) 21:26, 23 June 2017 (UTC)
- It wasn't entirely clear in the announcement and there was no time to get clarification before the publication deadline, so I thought it would be best to stick to their lingo. I'd like the record to show that I did try to figure it out though!!! —A L T E R C A R I ✍ 10:08, 24 June 2017 (UTC)
- The term "audience vertical" was introduced in the 2015 re-org. The idea is that job functions (like coding or testing) are horizontal slices through an organization, while products and features are vertical slices. In the foundation, each "vertical" focuses on a specific audience (e.g. Readers), and at least in theory each one contains personnel of all the disciplines it needs to be relatively self-sufficient. Each "vertical" is smaller than a department, but usually larger than a team. KSmith (WMF) (talk) 18:42, 26 June 2017 (UTC)
- Vertical market probably, and yes, the announcement is very heavy on Silicon Valley biz jargon. - Bri (talk) 21:26, 23 June 2017 (UTC)
- I know I'm confused. As I recall, the community re-elected Raystorm and Pundit as well as returned Doc James to the seat he was wrongly removed from. I can see that WMF keeps several editors in non-voting positions (no surprise) but I guess I don't understand what Doc's position means. Chris Troutman (talk) 10:09, 24 June 2017 (UTC
- I was wondering and asked Doc James in this secion of his user talk page. The !election for the WMF Board only provides advice / recommendations to the Board, which controls the appointment of its own members. The meeting where the decision will be taken is not until August. Apparently, if Doc James is appointed to the Board, he would also move from a non-voting / advisory position on the Committee to which he has been appointed to become a full voting member of it. He sees this advisory appointment as a positive sign for the actions of the Board in appointing its new members in August, so hopefully this (temporary) advisory appointment is good news. EdChem (talk) 14:20, 24 June 2017 (UTC)
- "We trained hard but it seemed that every time we were beginning to form into teams, we would be reorganized. I was to learn later in life that we tend to meet any new situation by reorganizing. And what a wonderful method it can be for creating the illusion of progress while producing inefficiency, confusion and demoralization." -- Attributed to Gaius Petronius Arbiter (c.27-66 AD).
- (This was attributed to Gaius Petronius Arbiter (c.27-66 AD) by Robert Townsend in his book Up the Organization (1970). The original source appears to be Charlton Ogburn, Jr. writing in Harper's magazine (1957). --Guy Macon (talk) 07:38, 28 June 2017 (UTC)
Op-ed: Facto Post: a fresh take (27,399 bytes · 💬)
- One tried-and-true method of sharing sister-project data on Wikipedia was through links on the bottom of templates. Author, artist, and other templates were able to include links to the invaluable and informative pages at Wikiquote, Wikisource texts (adding the descriptor "texts" to "Wikisource" 'fixes' a not-quite-clear term), Commons, etc. After being used for years, a 2015 RfC, which included late-arriving evidence of their six-year problem-free use on the main {{Wikipedia}} template that even the closer missed, allowed editors to remove them. As far as I've seen only one editor has done so, and I've been advocating for their return ever since. Here is what one looks like. Adding these links back, and limiting them to three a template, will add a world of information to the readers and provide a logical sister-project crossover. Hopefully they will be returned by 2030 (if not next Monday). Thanks for your op-ed, nice work. Randy Kryn (talk) 10:26, 23 June 2017 (UTC)
- Thanks, I wasn't aware of that issue, and will take it on board. It is the sort of area in which Wikidata might usefully be factored in, and clearly hasn't yet been. Charles Matthews (talk) 12:04, 23 June 2017 (UTC)
- I like that this article got me interested and now I want to read more of this. This op-ed is a series of unanswered questions - "How would a data scientist say that Wikidata is underrepresented in the Wikimedia strategy planning?", "How can the Wikimedia community keep people focused on content by satisfying requests for personalized presentation of content?", "What tools are likely to become available to reuse Wikidata content, and why should the Wikimedia community care?". I have my own thoughts about these things even if I hardly understand them myself. It is nice to see Wikidata writing in The Signpost. Blue Rasberry (talk) 16:41, 23 June 2017 (UTC)
- Tim Berners-Lee is concerned about the centralization of the Internet to a few large sites, and is working to reinvigorate decentralization; it seems to me that centralizing facts to a single database is a step in the wrong direction. You are selling a site where a FACT can quickly and easily be changed with minimal oversight. What is to stop Wikidata from becoming the go-to source for Fake Facts? Wikidata does serve a useful purpose though, in connecting the many different language Wikipedias. We don't allow content forks in a single language, but forks in other languages could serve a useful decentralization and quality-control function. Wikidata itself shouldn't be editable, rather it should constantly be monitoring the identical facts as stated in multiple languages. When all languages agree on a data item, then Wikidata may "publish" that as a "certified" data item. If even a single language edition has a different value for the data "fact", then Wikidata should flag this as a "disputed fact" for the attention of editors who will either revert the vandalism of the outlier or update all the out-of-date editions with the new value of the data item. wbm1058 (talk) 18:05, 23 June 2017 (UTC)
- I think the first point is more of a debating point: surely the multiple routes for reusing Wikidata content, which is freely licensed, make the site different in kind from, say, Facebook. The second point should be well taken: Wikidata is at a point in its history where the community agenda should be turning in the direction of data integrity (people do use watchlists there, by the way), but also "manual of style", in other words more explicit discussion on "data models". As for multiple languages, I'd like to make the points in the other direction. Firstly, that Content translation has huge potential. One obstruction is that reusing references is often difficult. I think that underlines the need for some "citation reform" thinking. Secondly, anomalies between different language versions. "Death anomalies" have been monitored for years now. The idea could well be scaled up. Thank you for raising these big issues. Charles Matthews (talk) 06:58, 24 June 2017 (UTC)
- Very worthy points, Charles. Tony (talk) 12:24, 24 June 2017 (UTC)
- Mindless, automated content translation was pushed out too fast. Content translation might better help with ensuring data integrity. Flag content where the translated content of another language is at odds with what the content in your native language says, for further investigation. There is strength in having multiple points of failure, with each language representing a single point of failure. Pushing out Wikidata that is maintained in one database with a single point of failure, without adequate content controls in place, could cause more harm than good. wbm1058 (talk) 13:19, 24 June 2017 (UTC)
- I guess (having given a talk on Thursday on Wikipedia's reliability) that the appropriate concept of "failure" is of failure to notice that data integrity has been harmed. It is more a question, therefore, of alertness.
- I think the first point is more of a debating point: surely the multiple routes for reusing Wikidata content, which is freely licensed, make the site different in kind from, say, Facebook. The second point should be well taken: Wikidata is at a point in its history where the community agenda should be turning in the direction of data integrity (people do use watchlists there, by the way), but also "manual of style", in other words more explicit discussion on "data models". As for multiple languages, I'd like to make the points in the other direction. Firstly, that Content translation has huge potential. One obstruction is that reusing references is often difficult. I think that underlines the need for some "citation reform" thinking. Secondly, anomalies between different language versions. "Death anomalies" have been monitored for years now. The idea could well be scaled up. Thank you for raising these big issues. Charles Matthews (talk) 06:58, 24 June 2017 (UTC)
- Under the "many eyeballs" doctrine, a change made in 100 places really is more likely to be noticed quickly. Defining the question more quantitatively, as I suggested in my talk, can start with talking about median and mean times to fix.
- We have to be concerned, fundamentally, with factors that keep the mean time high. Centralising to a so-called single point of failure does not harm the ambition to bring down the mean time to fix. Errors on Wikipedia can take between 48 hours (say – via someone's watchlist) and ten years to be corrected. Let's call that three orders of magnitude. Are you really saying that we should worry, when the choice is between a "broadcast" error, and individually maintained values on say, 100 wikis, only 10 of which may have patrolling comparable to what goes on here? Charles Matthews (talk) 13:55, 24 June 2017 (UTC)
- There is too much reliance on "many eyeballs" to solve all the hard problems. That errors go years without being corrected is evidence that there is a shortage of eyeballs. The advantage of automated systems is that they can have thousands of eyeballs, while humans only have two. I can't be watching 100 wikis at once, but you can design automated systems that can watch 100 wikis at once, and throw a red flag when a data item on wiki #37 changes to something different than the other 99 wikis have. I spend relatively little time looking at my watchlist, because watchlists don't have any intelligence to filter out the benign changes and flag the problematic changes. The work queues I focus on have flagged with virtual 100% certainly an issue that needs to be addressed. I'm often the only editor working these queues. I have more queues than time. I'm like the boy with ten fingers trying to plug a Dutch dyke with 500 holes in it. You can propagate Wikidata out into the wild to 100 places in a few minutes that if bad can take human editors years to repair all the damage. How many eyeballs are there really watching the Wikidata anyway? Is there a list of Wikidatans by number of edits? My understanding is that the most prolific Wikidata editors are all bots. I don't know anything about what sort of BRFA process there might be on Wikidata, but on English Wikipedia WP:BRFA goes to extreme lengths to avoid allowing bots to spread trash en-masse. I have a bot that's been waiting six months for approval. wbm1058 (talk) 16:37, 24 June 2017 (UTC)
- We have to be concerned, fundamentally, with factors that keep the mean time high. Centralising to a so-called single point of failure does not harm the ambition to bring down the mean time to fix. Errors on Wikipedia can take between 48 hours (say – via someone's watchlist) and ten years to be corrected. Let's call that three orders of magnitude. Are you really saying that we should worry, when the choice is between a "broadcast" error, and individually maintained values on say, 100 wikis, only 10 of which may have patrolling comparable to what goes on here? Charles Matthews (talk) 13:55, 24 June 2017 (UTC)
- I have to say I think you may misunderstand. Let me make some comments. I think, though I have not tried this out myself, that it would be relatively easy for someone to copy their watchlist here on English Wikipedia to an equivalent one on Wikidata. That would be an application of the PagePile tool. In other words editors here who wanted to watch the content of infoboxes or anything else here drawn from Wikidata have a technically quite simple way to reproduce the sources of that content. (Things might be just a bit more complicated if an infobox used "arbitrary access" to pull in data from more than one Wikidata item.) A typical Wikidata item will be visited less often by bots doing incremental maintenance than a typical page here. So the Wikidata watchlist should be easier to monitor for substantive changes.
- Further, what you say about propagating Wikidata errors doesn't make sense to me. That model is true for translation: if an enWP article is translated for deWP, and then a correction is made to the English version, there remains a correction to make in the German version. On the other hand, if an error is introduced on Wikidata, and then corrected, the correction propagates in just the same way that the error does. Charles Matthews (talk) 06:42, 25 June 2017 (UTC)
- Charles, we're talking past each other a bit here. I had not seen PagePile before. "PagePile manages lists of pages". That doesn't really tell me much about how it might be useful to me. I don't see much in the way of documentation on how to use it. As I said, I don't make big use of my watchlist. I give it a cursory glance several times a day, yes, but I don't step through it item by item and examine each change. Most changes reported on my watchlist are ignored by me. As a "power user tool", it's rather weak. Perhaps some whose focus is edit filters or vandal patrol make better use of watchlists (mine isn't, I look more for good-faith errors – but my patrols for errors do catch a lot of vandalism as well). I patrol for these things.
- I get what you're saying about the data being hosted on Wikidata, I think. The data is "transcluded" to English Wikipedia from Wikidata, so the data cannot directly be edited on Wikipedia, one must go to Wikidata to change the data. Can you show me some examples of that? Is there a category for all such items, so they can be monitored? wbm1058 (talk) 13:32, 25 June 2017 (UTC)
- Yes, "talking past each other" is what writing an op-ed in the Signpost is designed to get round. PagePile is probably not adequately documented. The original blogpost gives a general idea: it is a utility that can translate lists and output them in various ways.
- Further, what you say about propagating Wikidata errors doesn't make sense to me. That model is true for translation: if an enWP article is translated for deWP, and then a correction is made to the English version, there remains a correction to make in the German version. On the other hand, if an error is introduced on Wikidata, and then corrected, the correction propagates in just the same way that the error does. Charles Matthews (talk) 06:42, 25 June 2017 (UTC)
- As for details of infobox use of Wikidata: Template:Infobox telescope is an example. It was converted to a Lua module that pulls in content from Wikidata around July 2016; so that the code contains #invoke. Your type of question is something like "which pages here use {{infobox telescope}}, and how would one get a list of the Wikidata items that correspond?" I'm not the cleverest at these things, but the query https://petscan.wmflabs.org/?psid=1133692 runs to list the English Wikipedia pages with the template, and the Wikidata items corresponding (final column). So, for this example, one can get a good idea where the data comes from.
- For a fuller answer, I would use Category:Infobox templates using Wikidata, which has 94 entries right now. I would modify the Petscan query so that the Templates&Links page used "Has any of these templates" for that list of 94. Charles Matthews (talk) 15:33, 25 June 2017 (UTC)
- It's interesting to see that an article like Green Bank Telescope's infobox is created by just {{Infobox Telescope}} – with no parameters at all! Essentially that makes Wikidata not a separate database at all, but a component of the Wikipedia database. As with Lua modules, an element that poses a learning curve. I've fiddled with Wikidata a bit, with mixed success. Sometimes I just leave something for others to fix, if I can't figure it out reasonably quickly. I find all those little pencils a bit distracting – isn't the [edit on Wikidata] at the bottom of the infobox sufficient? Noting also that other templates use Wikidata in a more subtle and less obvious way than {{Infobox Telescope}} does. A bit more challenging to vandalize... and fix. So not sure whether it's a net positive or not on a quality-assurance basis. Perhaps postive if equivalent "telescope" templates are used in other languages. Would be a plus with a system to ensure that the
{{Convert|2.3|acre|m2}}in the source text of the article and the 2.3 obtained from Wikidata were in sync. Also the article cites a ref. for the 2.3 but that ref. hasn't made its way into Wikidata. wbm1058 (talk) 20:25, 25 June 2017 (UTC)
- It's interesting to see that an article like Green Bank Telescope's infobox is created by just {{Infobox Telescope}} – with no parameters at all! Essentially that makes Wikidata not a separate database at all, but a component of the Wikipedia database. As with Lua modules, an element that poses a learning curve. I've fiddled with Wikidata a bit, with mixed success. Sometimes I just leave something for others to fix, if I can't figure it out reasonably quickly. I find all those little pencils a bit distracting – isn't the [edit on Wikidata] at the bottom of the infobox sufficient? Noting also that other templates use Wikidata in a more subtle and less obvious way than {{Infobox Telescope}} does. A bit more challenging to vandalize... and fix. So not sure whether it's a net positive or not on a quality-assurance basis. Perhaps postive if equivalent "telescope" templates are used in other languages. Would be a plus with a system to ensure that the
- For a fuller answer, I would use Category:Infobox templates using Wikidata, which has 94 entries right now. I would modify the Petscan query so that the Templates&Links page used "Has any of these templates" for that list of 94. Charles Matthews (talk) 15:33, 25 June 2017 (UTC)
- I'm afraid I must disagree fundamentally with Tim Berners-Lee's solutions to the problems he identifies. Control over personal data, spreading misinformation, and political advertising are real enough (although commercial advertising in general is at least as much a problem as political). Nevertheless I can't agree that the solution is to fragment the conduits for these activities. The solution is going to be the continued and increasing success of projects like Wikipedia, which are based on models of personal privacy, verifiability of data, and neutrality of content. From that perspective, it's important to build and grow Wikimedia projects, and to be vigilant in defending them from the sort of threats that Berners-Lee identifies. Centralising facts to a reliable, trusted, comprehensive database is a step in the right direction, because such a database that became the pre-eminent source of data – in the way that Wikipedia has become as a source of encyclopedic information – would be our strongest hedge against privacy bandits, fake-fact fabricators and targeted exploiters. The antidote to being lied to, is to find somebody whom you trust to tell the truth. --RexxS (talk) 12:43, 24 June 2017 (UTC)
- You included a link to wikt:vision thing, which is unreferenced and therefore problematic. Shame on editors adding content without making it verifiable. I don't think Wiktionary should include phrases, at all. Something some guy said once isn't worthy of inclusion, to my mind. Further, there was a link from Wiktionary back to here, pointing to a disambig page where I had to remove the unreferenced definition per WP:DISAMBIG because we don't host content on disambig pages, just links to other pages. No amount of integration changes our poorly-written products created by slipshod editors. Chris Troutman (talk) 09:53, 24 June 2017 (UTC)
- You are entitled to your opinion. It is not mine. As it happens, Wiktionary is set to be integrated into Wikidata. On Wikidata, checking what is referenced and what is not can be automated, making maintenance easier. Via tools, links to dab pages can be found, again simplifying that maintenance task. String searching to find page titles with spaces in ... need I go on? I think the perspective I'm advocating has something to say to about the sentences numbered 1, 3 and 5 in your comment. What you add in sentences 2, 4, and 6 provides examples of comment of another kind. As I say, the opinions you are entitled to. I certainly don't share that tone in our discussions, if I can at all help it. A tradition here of random abuse of the communities in smaller sister projects is more honoured in the breach than in the observance, I feel. Charles Matthews (talk) 11:32, 24 June 2017 (UTC)
- You should not attribute to malice that which can be explained by simple indignation. Whereas you seem to perceive an attack leveled at you or Wikidata, I mean to communicate a general dislike of our editors, who leave us problems to fix. Chris Troutman (talk) 11:41, 24 June 2017 (UTC)
- Well, what I perceived was a certain rhetorical strategy of interleaving technical comments with divisive remarks. Those apparently were aimed at the Wiktionary community. I certainly did not take it as ad hominem; and I would say the term and imputation "malice" is one you are introducing here. Anyway, the context is the Wikimedia movement strategy exercise. If you have contributed to it on the appropriate use of cross-project shaming, I'll give your view due consideration. Charles Matthews (talk) 11:59, 24 June 2017 (UTC)
- You are entitled to your opinion. It is not mine. As it happens, Wiktionary is set to be integrated into Wikidata. On Wikidata, checking what is referenced and what is not can be automated, making maintenance easier. Via tools, links to dab pages can be found, again simplifying that maintenance task. String searching to find page titles with spaces in ... need I go on? I think the perspective I'm advocating has something to say to about the sentences numbered 1, 3 and 5 in your comment. What you add in sentences 2, 4, and 6 provides examples of comment of another kind. As I say, the opinions you are entitled to. I certainly don't share that tone in our discussions, if I can at all help it. A tradition here of random abuse of the communities in smaller sister projects is more honoured in the breach than in the observance, I feel. Charles Matthews (talk) 11:32, 24 June 2017 (UTC)
- It's really more than time that references were handled systematically. Your point that presentation should be separated from content must be the right way to go. The implication is that a citation template (or equivalent Wikidata) should become the standard, with each element (forename, surname, ...) separated. The user can then choose to see John C. Doe; Doe, John C.; Doe J.C.; or Doe JC exactly as she pleases: and the same for all other aspects of reference formatting. This would make both editing (all articles structured alike) and reading (you see refs as you like 'em) easier and more pleasant for everyone. Chiswick Chap (talk) 09:17, 26 June 2017 (UTC)
- Glad someone is on my side! I would say that is a little way off, though. I recall that having dates displayed as the user wished (e.g. DD-MM-YY versus MM-DD-YY) was tried and withdrawn. The infrastructure to handle "references with preferences" would be hugely more. Charles Matthews (talk) 09:27, 26 June 2017 (UTC)
- Charles, sorry to be the bearer of bad news. I can see you have a lot invested in this. I agree that the complexity of our referencing templates and systems is something that needs to be improved. So I went looking into that, and stumbled into another problem: Template:FJC Bio. This template was dependent on numeric ID numbers at the Biographical Directory of Federal Judges website, and these ID numbers were installed as a Wikidata item. Guess what, the website changed their URLS so that the old ID numbers don't work anymore! This was also reported at d:Property talk:P2736#Links broken. First, a patch was installed to use the Wayback Machine, then a new parameter was added that bypasses the obsolete Wikidata item. Now one of our most active and experienced editors (who ranks just outside the top 100 by all-time edit count) is using WP:AWB to add parameters back to the template. I'm not sure of the merits of porting third-party website IDs that are subject to change at any time, at the whim of their webmaster, to Wikidata. Is there a way to efficiently update these with an AWB-type of tool? wbm1058 (talk) 16:32, 26 June 2017 (UTC)
- Indeed, bad news. The Wikidata view would be, naturally, that we are interested in stable identifiers. Which properties are admitted on Wikidata is a community decision, and identifier properties would be discussed on the assumption that the identifiers are stable. Which is only an assumption, of course: institutions do not feel bound to keep identifiers stable under all circumstances. So, in the case of Biographical Directory of Federal Judges ID (P2736) it seems that the webmaster or someone higher up the food chain wasn't so concerned?
- With 4000+ properties, those being (I believe) over 50% of identifier type, this kind of glitch will turn up, regularly I suppose. With Art UK artist ID (P1367), which used to be "BBC Your Paintings artist ID", they migrated their site away from the BBC's; but had the savvy to leave redirects. That made it a quick bot job to harvest the new IDs, and the transition was quick.
- So this case sounds a bit worse. If websites simply change everything (which happened for example with https://www.encyclopediaofmath.org, before Wikidata), then templates here stop working. And links from anywhere stop working. Charles Matthews (talk) 17:50, 26 June 2017 (UTC)
- To answer your question on a technical level: if the only solution is to scrape or rescrape the website, the next step can be to use the mix'n'match tool. A new catalog for it can be created by a third party, using the import page for the tool, from some data in columns that includes a snippet from each biographical page. Then various types of matching can be applied (automated, semi-automated, gamified). Probably less skill required than AWB, in some sense. Charles Matthews (talk) 19:05, 26 June 2017 (UTC)
- External sites will always be subject to the whims of their owners to restructure them. However, the penalty suffered in search engine rankings for sites that break incoming links is now so great that it is far less likely to happen on any established site. The solution for Wikidata is to drop properties that turn out to be unstable as being more trouble than they are worth. --RexxS (talk) 20:03, 26 June 2017 (UTC)
- In the broader context of (for example) the 400+ datasets in mix'n'match, there is a clear need for periodic rescraping, anyway. The Web is a dynamic place: identifiers change piecemeal, and are added to, as well as being subject to clumsy mass link rot. I know the discussed type of solution here, which is still at the string-and-sealing-wax stage of stored regexes, AFAIK. But, while it would indeed be sensible to stop bothering about sites which show themselves to be unworried by the issue, I expect a practical form of power archiving for sites with identifiers to emerge out of the existing set of ideas.
- I mean, saving bits of distinctive content so that search can be used is not beyond the wit of man; and automation can then be used. Doubtless sites that actually want to implement anti-scraping technical measures can spend resources to do that, creating an arms race. But that really is going to be effective only where it is done ab initio, not in preventing rescraping. Charles Matthews (talk) 04:57, 27 June 2017 (UTC)
- Comment Many of us who write large amounts of Wikipedia want to see a fair bit of reference data within the text of the article as we edit (such as year of publication, title, pmid, etc). How would pulling data from WD affect this? A single identifier within the text is (1) unclear (2) too easy to vandalise Doc James (talk · contribs · email) 17:53, 26 June 2017 (UTC)
- As far as I can see (and I'm certainly no expert on Lua, if that is the route taken), the various fields in a reference template could be filled up as an infobox is. The contents would be taken from a Wikidata item that housed the data for a given paper. You raise two points, firstly (I think) that this way should be something that could be previewed. I imagine that could be done. The second, that intentionally (or not) the wrong paper could be cited. Well, I think that is a criticism that could be made of any attempt to "tokenise" references in place, on Wikipedia. I'm not sure that I want to attempt a slick answer to that point. Vandalism is a background problem here.
- It is certainly true that changing one token to another would not be perspicuous, from the point of view of patrolling: yet it would be clear enough that some change had been made. There would at least be a trade-off: a token could mean that, across all Wikipedias, one could see where a given paper was used. If findings were later revised, it would be possible to track all uses and see if the text needed to be changed. Translation could be simplified. Charles Matthews (talk) 19:20, 26 June 2017 (UTC)
- We already have infoboxes that draw references from Wikidata and the Lua code is already written. For that case, there are no tokens involved as the reference is directly related to the claim it supports, so it can be fetched at the same time as the claim is. The main barrier to further development is the display problem. While we have no agreed standard for references, they will have to be displayed in the same manner as the owner of the article demands (the CITEVAR problem), which is impossible to code automatically. It would be nice to think we could separate the content of a reference from its presentation (e.g. the CS1-style citations are capable of being displayed in MLA-style by setting a parameter), but there's nowhere other than cookies to store a user's preference unless they are a registered editor. Part of the reason why the date formatting experiment failed was that less than 5% of our readers could make any use of it. --RexxS (talk) 20:03, 26 June 2017 (UTC)
- Indeed, I referred to the issues round WP:CITEVAR in the article; and called the Preferences solution "futuristic", for that reason, and for the technical reasons RexxS mentions. CITEVAR is supported, in the guideline page, by reference to an ArbCom principle of 2006, from Wikipedia:Requests for arbitration/Sortan. I was one of the Arbitrators of the time, this being one of my early cases.
- This principle could be revisited. I don't see why not: it wouldn't offend me to be told that I didn't have a crystal ball at the time. (There was a large backlog of cases, I recall. Fred Bauder made herculean efforts to get on top of it.) ArbCom has never been the legislature, and was concerned at the time about disruptive editing, as the decision page makes clear. Charles Matthews (talk) 04:39, 27 June 2017 (UTC)
Recent research: Utopian bubbles: Can Wikipedians create value outside of the capitalist system? (13,115 bytes · 💬)
Nicely done. --Piotr Konieczny aka Prokonsul Piotrus| reply here 07:37, 23 June 2017 (UTC)
- Indeed! Great reviews, thank you very much. (And I'm glad there is someone reading the Marxist theoretical approach to Wikipedia, because I'd rather not have to do it myself.... ;) ) The Land (talk) 15:55, 23 June 2017 (UTC)
- Wikipedia, Work, and Capitalism is a 350 page book that I have not finished reading so I cannot speak to all of it, but Dorothy's summary of the premise is fair enough. I do worry about commercial interests exploiting the goodwill of Wikimedia contributors. At the same time, I also feel like Wikimedia projects are significant beyond just the content that they host. Among the top 500 websites as ranked by Alexa Internet, there are only a few noncommercial organizations present (checked October 2016): 5. Wikipedia 99. BBC (US), 105. BBC (UK), 137. The Pirate Bay, 192. Mozilla, 227. Internet Archive, 234. National Institutes of Health, 423. United States Postal Service. Among those, only Wikipedia and maybe Internet Archive are seeking to provide a community space for everyone to participate in noncommercial service for everyone else. I feel like Wikipedia might be the last public space that the world might know for some generations, because in every other non-niche outlet there are commercial interests grabbing for any scrap of data or attention that they can extract from anyone. If public media ever mattered then Wikimedia projects are preserving that community space and trying to stake claims to keep it for the future. If it is ever lost then maybe it could be gone for a long time. It is unfortunate that so much Wikimedia project success depends on the labor of so few volunteers who give so much and get use for their research, writing, photography and the rest by commercial organizations who take but do not give back their fair share or social due. Blue Rasberry (talk) 19:50, 23 June 2017 (UTC)
- Rather interesting research. Thanks for pointing us to the paper by Kummer et al. It is hard to believe that is took more than a year and a half until it has reached the community. — You might like to know that Günter Schuler as early as 2007 in his book Wikipedia inside (207ff, 214ff) argued that the blossoming of Web 2.0 which Wikipedia is a part of was after all mostly due to the wave of neoliberalism which had increased an interest in "sense" and idealistic values vs. economical effectiveness, metrics etc., fuelling the influx of editors to blogs, and wikis in the period 2000—2005. So there seems to be a constant point it the Zeitreichen, or those rich in time and leasure, mostly keep editing the web.--Aschmidt (talk) 22:12, 23 June 2017 (UTC)
- A minor comment: The authors are not three economists from the Centre for European Economic Research (ZEW) in Mannheim, Germany, but rather: Michael Kummer (from Georgia Institute of Technology), Olga Slivko(an economist from ZEW), and Michael Zhang (Hong Kong University of Science and Technology). — Preceding unsigned comment added by 193.196.11.188 (talk) 08:44, 26 June 2017 (UTC)
- Always great to have new research on Wikipedia.
- "Wikipedia, work, and capitalism. A realm of freedom?"
- He claims that the anti-corporatist ideologies intrinsic to peer production and to Wikipedia are unrealistic because capitalism always finds a way to monetize free content.
- I'd disagree for two reasons: first off who says that such anti-corporatist ideologies necessarily have a problem with capitalism monetizing free content? For instance I don't have a problem with companies making profits from my any of my contributions online even without attribution (as long as my contributions themselves remain open in such a way that they could theoretically also be used for non-profit projects). Also companies monetizing free content can be constructive for society as well and within the current structure in many cases it might not be feasible (due to time/resources required) for non-profit projects to put such content to use in the same way.
- Secondly capitalism will simply be overcome. I'm stating this that confidently not only because our socioeconomic system has changed many times in human history but because everything points to our civilization collapsing / we as a species actually dying out if we don't manage to change our socioeconomic structures within the next few decades in ways that are so fundamental as to warrant a new name for the succeeding model. And imo Wikipedia is part of the paradigm that is already overturning capitalism from within and which already employs the logic of a (imo that) new model.
- One recurrent theme is that Wikipedia is part of a larger trend in gamification—a design technique developed in Human–computer interaction (HCI) to describe the process of using features associated with "play" to motivate interaction and engagement with an interface. One example he gives is that editors report that they find Wikipedia's competitive and confrontational elements to be game-like.
- I don't think interactions with and on Wikipedia could largely be described as applying gamification. Gamification is the active application of typical game playing elements such as point scoring, awards and competitions to non-game / work-like processes. None of that is really done on Wikipedia - there are edit counts, thank yous and barnstars etc but most don't pay attention to them / use them and mostly (and most importantly) they're not actively applied to motivate engagement. There is some low-profile, marginal gamification going on on Wikipedia - but describing Wikipedia as being "part of a larger trend in gamification" would imo be plain out wrong.
Even less prevalent examples of gamification on Wikipedia would be: CitationHunt and The WikiData game and two suggested gamification elements would be: an auto-congratulatory feature and Edit counts of subject-area editors / WikiProject leaderboards. - Still, it’s highly questionable whether the 8 interviews, which mainly focus on the Swedish Wikipedia, are a sufficient sample size to make his claims scalable.
- Good remark. Such a type of interviews is an outdated mode of gaining insights / feedback and I don't think they are sufficient.
- To him, Wikipedia is symptomatic of the devaluation of digital work, when in past generations, making an encyclopedia might be a source of income and employment opportunities for contributors.
- What a strange way to look at this. It does not devalue digital work. Actually it values knowledge so highly that it has to be disassociated from monetary incentives. Societally highly constructive work such as contributions to open knowledge, open data and online encyclopedias should actually be valued by society so that people who engage in such can allocate their full time to it. But it isn't. Which means society should to change. And with that − at least in the case of Wikipedia − I'm less referring to the mentality of people but to the societal structures that organize people's self-sustenance and work-allocation (such as the kinds of "monetary income" and "employment" we know of thus far).
- But from his view, attempts at a “counter-economy,” “hacker communism,” or “gift economies” (239, 303) are prone to manipulation, because we can’t create utopian bubbles within capitalism that aren’t privy to its influence.
- That's one reason why projects such as Wikipedia need to remain highly adaptive and find proper mechanisms and measures to thwart such "manipulations". I don't think Wikipedia has been manipulated at its core even though its surrounding capitalism causes e.g. marketers to attempt to use it in the most beneficial way.
- why Wikipedians might feel like they are playing when they are really working
- I don't think that Wikipedians in general or in large numbers "feel like they are playing when they are really working". I think it's a new mode of engagement that is not accurately described as either. Something akin to prosumptive, interactive learning/contributing. To me it's more fun than playing because you will actually achieve sth / have an impact / be constructive in a meaningful way.
- Lund makes a compelling case that capitalism instrumentalizes freely-produced knowledge for its own monetary gains. Meanwhile, he says, Wikipedia's design and its heavily ideological agenda, make it difficult for the community to address the issue.
- Did he also explain why that would be an issue at all?
- How does unemployment affect reading and editing Wikipedia ? The impact of the Great Recession
- Concerning the remarks of what data the researcher could also have used: it would be a good idea to have researchers announce (the subject of) their research somewhere so that people can help by providing relevant data, crowdsource information and provide technical support etc. This should probably be done for all kinds of research (in streamlined manners) but let's start with research on Wikipedia.
- And as a relevant sidenote I've become jobless recently and you'll likely to see my contributions spike (once I got some other issues fixed) as I now have more time for Wikipedia (& FOSS) which I consider way more constructive for society and self-actualizing than work within the market economy, generating profits etc. Sadly I won't be able to sustain this situation (of joblessness) for long. Note that imo that doesn't really affect what I stated in my comments about the book above - I enjoy being jobless (as long as I can also safely meet my basic needs etc; won't be able to sustain it for long but maybe I can establish a similar situation in a year or so) and I'm not frustrated with the current system but think it's outdated.
- "Extracting scientists from Wikipedia"
- There should be a global IT system which in effect maps people to their expertise and skills which can then be effectively made use of by those in need for such, aiming to collaborate or exchange or engage in relevant projects. I don't think Wikipedia is very efficient in such as it only features a fraction of notable scientists. It needs a new project / website to do this (which might start off with data gained from Wikipedia).
- "Where the streets have known names"
- This might be relevant to Wikipedia:Smart city uses of Wikipedia.
- –
- And as a sidenote, relevant to my comments above, it imo also needs a proper IT system which indexes research and allows feedback and continuation etc beyond other academic research and the press simply picking up/referencing it.
- --Fixuture (talk) 22:38, 28 June 2017 (UTC)
- @Fixuture: I agree that Wikipedia isn't gamified in the sense that one might expect (compared to for instance Stack Overflow), but as you mention there are places where it pops up. In addition to the ones you point to, there's the Wikipedia Adventure, which has recently been published at a research conference (see this blog post for more info). Secondly, there's the WikiCup, which I studied in our 2015 CSCW paper about quality improvement projects (PDF here) and found some behaviour that was very similar to what you see when it comes to badges in Stack Overflow: participants get points for Good Articles, but nothing for B-class quality, so they rarely (if ever) stop at the latter. Given that these game-like elements pop up in several places, I'm not surprised that participants would describe Wikipedia in ways that can be interpreted as the site being "game-like". Cheers, Nettrom (talk) 14:30, 30 June 2017 (UTC)
Technology report: Improved search, and WMF data scientist tells all (1,135 bytes · 💬)
The errors messages I'm getting when I try to add the suggested code above to my commons.css suggest that it should be just: #mw-interwiki-results { display: none }. - Dank (push to talk) 13:59, 23 June 2017 (UTC)
- I created a new RfC to settle the Wikibooks issue. Feel free to express your opinion there. Kaldari (talk) 21:59, 23 June 2017 (UTC)
Why are results from Wikidata excluded? It adds real value to the search results. Often the results of Magnus's search extension are of higher quality that currently provided. Thanks, GerardM (talk) 09:44, 24 June 2017 (UTC)
- Add all the search results you like, as long as "#mw-interwiki-results { display: none }" works (and more visible ways to turn it off would be better). - Dank (push to talk) 11:56, 24 June 2017 (UTC)
Traffic report: Wonder Woman beats Batman, The Mummy, Darth Vader and the Earth (1,514 bytes · 💬)
- Thanks for the list. It's always a wonderful insight to what everyone's latest distraction is :) —TheDJ (talk • contribs) 09:24, 23 June 2017 (UTC)
- I'm afraid to make the change because I might be wrong, but Steve Scalise's condition would not have "degraded" if it changed from "imminent risk of death" to "critical". Unless I'm missing something. — Vchimpanzee • talk • contributions • 19:40, 12 July 2017 (UTC)
- @Vchimpanzee: I am not sure, but here was my source [1]. Eddie891 Talk Work 22:52, 12 July 2017 (UTC)
- I think I'm right after looking at that.— Vchimpanzee • talk • contributions • 13:52, 13 July 2017 (UTC)