This is an archive of past discussions about Domain Name System. Do not edit the contents of this page. If you wish to start a new discussion or revive an old one, please do so on the current talk page.
In the section "How the DNS works" it asserts that the "browser starts out knowing only the IP address of a root server", which provides it with the proper subordinate server. Yet, in fact, a web browser uses whatever DNS server is specified for the client; this is usually the DNS server of their ISP, not the root server. AFAIK, the root servers are rarely directly queried by clients. I don't know the proper way to correct this. Centrx22:26, 17 May 2004 (UTC)
not only that but the browser just makes a system call to the operating system resolver library like gethostbyname() and gethostbyaddress(), this stub resolver then queries the dns, and the dns is not the only possible name resolution system, there is also /etc/hosts lmhosts winz and other micrsoft monstrosoties and nis, nis++ and other sun monstrosities.
I corrected this. It's actually the ISP's DNS server that has the list of root servers. I'm going to do further clarification when I have some more time. Technically it's not the "browser" that does the DNS querying at all, it's actually the TCP/IP stack in the computer. I also don't want the article to become overly technical so I'll have to figure out a way to get that in there without making the whole thing unnecessarily complex.
Gutzalpus 19:10, 19 Jul 2004 (UTC)
No, actually it's not the Internet Protocol stack which does the queries (think about the "layering violation" concept) but the resolver library, which is usually one of the system libraries and probably runs in the same addresses space of the browser. --Md 21:31, 23 Jul 2004 (UTC)
DNS name resolution
The process of resolving DNS names is much like finding a name in a telephone book. You dont just pick your phone book and start looking for the desired name on the first page and keep turning the pages until you find it. Like a telephone book, the DNS name structure is broken down into smaller categories that can be searched more easily and logically for a name/
|Martoh|
It would be worth describing how hosts normally get their DNS server's IP address(s) in the first place: As I understand it, it's typically from a DHCP server (at the same time it receives it's own IP address). In the case of that DHCP running on a home router, it may in turn have got it from the ISP's DHCP server - alternatively, if the ISP has assigned the line a fixed IP address and isn't providing DHCP (e.g., many cable-based suppliers), the home router must have it supplied during the router's initial set-up. Clearing this up would make it easier to understand how most load is kept from the root servers/diverted to the ISP's servers, how ISP's can return false or misleading results, etc. Having each host (PC, Printer, etc) manually configured with a DNS address would be very much the exception these days.Nimrod54 (talk) 02:53, 5 July 2014 (UTC)
By clicking the “Save Page” button, you are agreeing to the Terms of Use and the Privacy Policy, and you irrevocably agree to release your contribution under the CC-BY-SA 3.0 License and the GFDL. You agree that a hyperlink or URL is sufficient attribution under the Creative Commons license.
Please give us a call at 704 for more information.
I believe that the table at paragraph "DNS message format" is a little bit misleading, because the sections containing RRs (Question, Answers RRs, Authority RRs, Additional RRs) are actually of variable length, but they're indicated as starting at a fixed octet offset. The fact that they're of variable length is cleary said in the paragraph "DNS resource records".
Moreover, in the paragraph "DNS resource records" I'd add the detail on how the NAME labels length is specified. Quoting RFC 1035: "Domain names in messages are expressed in terms of a sequence of labels. Each label is represented as a one octet length field followed by that number of octets. Since every domain name ends with the null label of the root, a domain name is terminated by a length byte of zero".
Glavepp (talk) 09:56, 22 April 2015 (UTC)
External links modified
Hello fellow Wikipedians,
I have just added archive links to one external link on Domain Name System. Please take a moment to review my edit. If necessary, add {{cbignore}} after the link to keep me from modifying it. Alternatively, you can add {{nobots|deny=InternetArchiveBot}} to keep me off the page altogether. I made the following changes:
When you have finished reviewing my changes, please set the checked parameter below to true to let others know.
This message was posted before February 2018. After February 2018, "External links modified" talk page sections are no longer generated or monitored by InternetArchiveBot. No special action is required regarding these talk page notices, other than regular verification using the archive tool instructions below. Editors have permission to delete these "External links modified" talk page sections if they want to de-clutter talk pages, but see the RfC before doing mass systematic removals. This message is updated dynamically through the template {{source check}} (last update: 5 June 2024).
If you have discovered URLs which were erroneously considered dead by the bot, you can report them with this tool.
If you found an error with any archives or the URLs themselves, you can fix them with this tool.
That reference once lead to this kind of thing, the bot instead chose the last available snapshot, which was a redirect eventually leading to this different kind of thing, which is overly long and doesn't substantiate the point --one registrar covers multiple TLDs. The adjoining reference is a dead link too. I'm going to remove both. ale (talk) 18:32, 18 December 2015 (UTC)
Section 0 is too long
Since we —IMHO correctly— decided to not merge various DNS pages, we should at least try and avoid repeating the same concepts in the same page.
Obviously it is not convenient to explain in an introductory, yet exhaustive style all of the content of DNS RFCs in a single page. An alternative is to just touch on concepts, one per subsection, using {{Main}} to direct to more detailed explanations. In particular:
The lede should be a few sentences in one or two paragraphs,
Section "History" seems to be too short, given that we don't have a "History of DNS" page,
Section "Function" could possibly be renamed "DNS vs phonebook",
Section "Structure" conveys the meaning of the hierarchy, so it is important to non-technical users,
From Section "Operation" onward, the content has to be more technically oriented. It may need some rearrangements in order to be more easily grasped. Some illustrations or tables might improve understanding as well; I'm aware Kbrose (talk·contribs) removed the message format table, but the remaining "bit-a-bit" description is not quite readable either... Perhaps we should have a real resource record page? Hm...
It scares me a bit that this article is quality B. I don't want to spoil it. Knowing someone takes a look at my changes would help, so please add your opinion below.
I have just modified one external link on Domain Name System. Please take a moment to review my edit. If you have any questions, or need the bot to ignore the links, or the page altogether, please visit this simple FaQ for additional information. I made the following changes:
When you have finished reviewing my changes, you may follow the instructions on the template below to fix any issues with the URLs.
This message was posted before February 2018. After February 2018, "External links modified" talk page sections are no longer generated or monitored by InternetArchiveBot. No special action is required regarding these talk page notices, other than regular verification using the archive tool instructions below. Editors have permission to delete these "External links modified" talk page sections if they want to de-clutter talk pages, but see the RfC before doing mass systematic removals. This message is updated dynamically through the template {{source check}} (last update: 5 June 2024).
If you have discovered URLs which were erroneously considered dead by the bot, you can report them with this tool.
If you found an error with any archives or the URLs themselves, you can fix them with this tool.
I removed following paragraph as it conveys incorrect information. It reads as if the Sender Policy Framework and DomainKeys are now using they own DNS record type (instead of TXT). While a SPF record was introduced it was later discontinued in favor of using TXT record. This is documented in the List of DNS record types article.
I also did not find the paragraph particularly relevant.
The Sender Policy Framework and DomainKeys were designed to take advantage of another DNS record type, the TXT record, but have since been assigned specific record types. — Preceding unsigned comment added by Arekkusu.r (talk • contribs) 06:43, 9 February 2019 (UTC)
Semi-protected edit request on 27 December 2019
This edit request to Domain Name System has been answered. Set the |answered= or |ans= parameter to no to reactivate your request.
The statement that IETF published RFCs 882 and **3 is incorrect: these two RFCs were published in November 1983, predating the first IETF meeting, which was held in 1986 (I was one of the 21 attendees). LixiaZ (talk) 04:40, 27 December 2019 (UTC)
I cannot see any publisher's information in the RFCs and IETF was formed in 1986. The current wording is:
Are there any opinions on wording for a possible change? Perhaps something like this:
The original specifications in RFC 882 and RFC 883 were published in November 1983.
A link to Paul Mockapetris is given in the preceding sentence. Perhaps the short paragraph above would be better if joined to the preceding paragraph. I temporarily disabled the edit request so a discussion about what to do can occur. At this time of year, we might need to wait a week or two for other views. Johnuniq (talk) 06:01, 27 December 2019 (UTC)
Either the above wording or a link to previous sentence as discussed would make sense. How about:
Mockapetris instead created the Domain Name System and the original specifications were published in RFC 882 and RFC 883 in November 1983
If you want to make either change or a similar one, I don't think it needs a full debate. The current wording is clearly not quite right, and if the new wording is not optimal, another editor can tweak it. Feel free to make a bold change. -- Sirfurboy (talk) 08:22, 27 December 2019 (UTC)
Does anyone know how I can set up my own domain name?
I mean, even the domain hosts have to get their one somewhere.
-DalekClock
Most people just use domain registrars. Domain hosts just have access to high level DNS servers, and the Internic ones (the major world ones), and they can sort it out with them. Reedy Boy13:02, 1 July 2006 (UTC)
I agree with this, and its notable that neither RFC 1034 nor 1035 use the term slave, and instead use master/secondary. RFC 8499 mentions previous use in rfc1996 which seems to be the outlier. I think that it is also reinforced by the fact that BIND and NSD documentations use both forms interchangeably, with secondary appearing to be used more. There will need to be some mention though of the alternate terminology as many configuration and zone files still reference it. Strangerpete (talk) 23:30, 20 June 2020 (UTC)
I forgot to add the quotes from RFC 8499 which is the Best Current Practice:
"Although early DNS RFCs such as [RFC1996] referred to this as a "slave", the current common usage has shifted to calling it a "secondary"
"Although early DNS RFCs such as [RFC1996] referred to this as a "master", the current common usage has shifted to "primary".
Currently, the types of DNS resolvers are described as non-recursive, recursive and iterative.
In my humble opinion, this distinction (without further explanation) is slightly confusing, as recursive and non-recursive should intuitively cover all the cases. In the RFC currently cited for this section[1], iterative is used as a different possibility altogether, and the section explaining the recursive and non-recursive mode somehow "forget" about the iterative mode, if I see this right? Any suggestions about how this could be clarified a little more? Any other opinions on whether it needs clarification at all?
Talitha 42 (talk) 17:58, 2 February 2018 (UTC)
IMO this section should be completely re-written. The word "iterative" doesn't occur at all in RFC 1035, and occurs only three times in RFC 1034, namely, on page 4. There it is clearly used as a synonym to "non-recursive". In the RFC, the terms "recursive" and "non-recursive" are only used to describe how DNS servers react to queries, not to describe how resolvers work.
As I understand it, resolvers always try to provide a definitive result, therefore providing "recursion" in a client application's point-of-view. They do this by iteratively querying other name servers, or by sending a recursive query to a DNS server that supports recursive queries (e.g. the DNS server provided by the ISP). — Preceding unsigned comment added by Mebuege (talk • contribs) 00:06, 25 August 2020 (UTC)
The following is a closed discussion of a requested move. Please do not modify it. Subsequent comments should be made in a new section on the talk page. Editors desiring to contest the closing decision should consider a move review after discussing it on the closer's talk page. No further edits should be made to this discussion.
Comments@Randy Kryn: can you point me to a policy stating that that would be the best idea? If I am reading WP:CRITERIA, then DNS would be the best name, because due to it's significant higher use it has greater recognizability. Therefore it's also the most fitting name regarding naturalness, because it has been referred to as DNS. Because DNS is already redirecting to this article, the precision would be fine. Other articles about networking protocols also use the abbreviation, such as HTTPS and MQTT, so consistency is also fine. PhotographyEdits (talk) 18:59, 31 March 2021 (UTC)
WP:COMMON seems to cover it. This one is a good recognizable name, changed to just the initials it would probably lose a good amount of recognizability among a percentage of readers. For instance, for DNS my first guess would have been a moving company, second, one of those UPS competitors. Randy Kryn (talk) 19:32, 31 March 2021 (UTC)
Oppose I very rarely agree with using an abbreviation as an article title as opposed to the proper term. – DarkGlow • 19:00, 31 March 2021 (UTC)
@PhotographyEdits: Can you point me to a policy or guideline stating that removing the letter "E" from every Wikipedia article and then coming to your house and throwing your computer in a swimming pool would be a bad idea? Wait...what? Oh, that's right. It is the job of the person who proposes a change to give a reason for making the change. Never mind.(The swimming pool idea has a certain appeal, though...) --Guy Macon (talk) 19:36, 31 March 2021 (UTC)
WP:COMMON covers your proposal as well. To quote: "Similarly, just because something is not forbidden in a written document, or is even explicitly permitted, doesn't mean it's a good idea in the given situation." The computer in the pool proposal, in the vein of Phil Ochs' "Basket in the Pool", may be a bit extreme in this situation. So I'll Oppose that, and instead double-down on "They have a pool?" Randy Kryn (talk) 19:58, 31 March 2021 (UTC)
Yes, and you make a well-thought out good faith case in favor of the change. My point of view on it is that lots of us who aren't computer literate enough to recognize the initials alone (as Guy Macon demonstrates below) do know what 'Domain Name System' describes. Randy Kryn (talk) 20:17, 31 March 2021 (UTC)
Oppose for the obvious reasons. WP generally spells out proper names of protocols, and this is also the name of an entire naming architecture. Acronyms like HTTPS and MQTT are exceptions rather than a rule, and should be avoided as titles. kbrose (talk) 19:21, 31 March 2021 (UTC)
Oppose per MOS:ACROTITLE: "Many acronyms are used for several things; naming a page with the full name helps to avoid clashes."
DNS may also refer to:
Deviated nasal septum, a displaced part of the nose
3,5-Dinitrosalicylic acid, an aromatic compound
Dinalbuphine sebacate, an analgesic
Direct numerical simulation, a simulation method in computational fluid dynamics
@Guy Macon: DNS has other meanings, yes, but the WP:PRIMARYTOPIC is the Domain Name System, DNS redirects here. If I compare the pageviews from the articles on the DNS disambiguation page, then the Domain Name System has the most views, by a *wide* margin. see here. I would argue that "Acronyms should be used in a page name if the subject is known primarily by its abbreviation and that abbreviation is primarily associated with the subject" from MOS:ACROTITLE does apply in this case. PhotographyEdits (talk) 20:06, 31 March 2021 (UTC)
Right now you have five editors who oppose and zero editors who agree with you. It looks like you need a better argument if you want to convince anyone.
BTW, here is a better NGRAM:[1] Many people use, for example "DNS lookup" or "domain name lookup" but not "domain name service lookup". --Guy Macon (talk) 20:36, 31 March 2021 (UTC)
@Guy Macon: I'm not very convinced by the counterarguments though. It's up to the closing administrator to weigh all the arguments against each other. Regarding your Ngram link, Domain name is already a separate subject and otherwise it seems to confirm my point that DNS is a far more widely used than Domain Name System. PhotographyEdits (talk) 22:33, 31 March 2021 (UTC)
Oppose - I'm not sure what this request to move/rename is really solving. Yes, people know it as "DNS", but when they come to this page (by searching for "DNS"), it is clearly defined as "Domain Name System". In fact, I would argue that having it defined in the title actually helps people understand what "DNS" is because they immediately get it spelled out. I have read MOS:ACROTITLE and do understand the use cases for having pages titled as acronyms. I'm just not sure that applies here because, as noted above, there are other uses of "DNS" outside the Internet space.
A curiosity question about your use of Google Ngram Viewer for data, as I am not very familiar with it. If that is searching books for the usage of "Domain Name System" versus "DNS", isn't it logical that "DNS" would enormously outrank the full "Domain Name System"? The general principle in books is to define an acronym at its first occurrence, and then use the acronym thereafter. So many books will have something like "..in the Domain Name System (DNS) there are..." and then will use "DNS" for the rest of the book. In any given book there could be only one mention of the full name and tens or hundreds of mentions of "DNS". If this is the case, is the Ngram Viewer perhaps not the best source of data for this discussion? (Perhaps Google search trends or something might be better.)
@Dyork: "Yes, people know it as "DNS", but when they come to this page (by searching for "DNS")", well, then the title should be DNS. The title should represent the name that people are likely searching for per WP:CRITERIA on naturalness, and the first sentence of the article should give the full name. PhotographyEdits (talk) 11:25, 1 April 2021 (UTC)
Oppose on first WP:CRITERIA Recognizability: A non-expert familiar with the internet will certainly have heard of a Domain, but outside technical circles, I wouldn't expect anyone to recognize a protocol acronym.
Second on Consistency: The two pointed out as examples are literally the only ones in the protocol suite that are not full titled. And I'd argue that HTTPS isn't the same since the average reader will have typed https into their browser at least once in their life, and quite possibly why they searched here in the first place - this same reason applies to DNS: nobody 'types' dns, but they all talk about domains. Strangerpete (talk) 01:35, 1 April 2021 (UTC)
I disagree that anyone could have the slightest idea of intent, past the singular word 'domain', or the combo 'domain name'. And one easy way to help clarify that is to do as WP:COMMONNAME emphasizes, use natural language titles; it would be easier for a reader to decide if they want domain names or the system, simply by reading the title.
To point, your book stats example is using the full title; if you search DNS vs Domain name, there is a 0.0001% difference in popularity; since we have no idea which 'dns' or which 'domain name' is the interest, it all seems moot.
That said, I could assume most here replying are technically literate, and well familiar with dns if they are following the talk page; arguably this means we probably can't be the best judge of Recognizability, and is perhaps one source of pushback. If we want a balanced discussion I think it might be important to invite a less-technical audience to the party for their two-cents. Strangerpete (talk) 17:13, 1 April 2021 (UTC)
Comment: many engineering and scientific documents use "Domain Name System (DNS) exactly once in the first paragraph and then use "DNS" hundreds of times. Ngrams are a nice tool, but like all tools they have limitations. BTW, when I personally run across "DNS" the first thing I think of is "Do Not Stuff", but that's because I design electronics that are produced on pick-and-place machines. The context makes it easy to figure out what is meant. --Guy Macon (talk) 02:32, 1 April 2021 (UTC)
@Guy Macon: I think that's a good criticism on the Ngram tool, but I disagree. For example, this news article from ZDNet talks about DNS but never explains what the acronym means. So anyone unfamiliar with it would search for DNS. As I've earlier pointed out, by counting the Wikipedia page views it shows that this article is by a wide margin the most viewed of all articles that could have "DNS" as an abbreviation. PhotographyEdits (talk) 11:37, 1 April 2021 (UTC)
The discussion above is closed. Please do not modify it. Subsequent comments should be made on the appropriate discussion page. No further edits should be made to this discussion.
New historical resource available (Nov 2020) about DNS and associated systems
The French and German version of this article have the upper image and other languages (e.g. Polish) have variations thereof. Whereas this article in English has the lower one.
Why do we not use the German one (or a variation thereof)? Is it incorrect or misleading? To me, being someone who is learning about what a DNS is, the upper one is much clearer. How about making a fusion of the English and German ones with useful names in the ″resource records with associated name″ instead of scribbles? 89.157.239.36 (talk) 06:51, 24 November 2012 (UTC)
The image File:DNS_in_the_real_world.svg depicts how DNS worked for most people fifteen years ago, but is really no longer accurate for most people, most of the time. Not that many ISPs operate their own recursive resolvers anymore, and not that many people use the ones they do operate. So labeling the recursive resolver as though it's somehow inherently operated by the ISP is definitely inaccurate. If there are any serious objections, I'll drop it, but I'll see if I can't whip up a more accurate diagram to replace this one. EVhotrodder (talk) 14:47, 30 August 2021 (UTC)
Trying to understand the first sentence
The first sentence of this article says:
The Domain Name System (DNS) is a hierarchical and decentralized naming system for computers, services, or other resources connected to the Internet or a private network.
Would you please give me an example or two of what a "service" would be in this context? Or, perhaps, is there an existing Wikipedia article about services connected to the internet? Butwhatdoiknow (talk) 16:47, 26 October 2021 (UTC)
I think what that language is referring to is how some companies install different Internet services on separate physical servers and assign each server its own unique DNS name. "Service" in this context refers to the server side of any application that runs over the Internet. For each kind of client, there has to be a corresponding server that listens for requests from clients. So there would be one server called "www" listening for inbound World Wide Web requests, one server called "mail" listening for inbound email requests, and so on. --Coolcaesar (talk) 19:41, 26 October 2021 (UTC)
Butwhatdoiknow, you link the word "services" to the article Server-side as though the two were equivalent, but this is another example of exactly the problem with your other suggested edit. This form of misleading over-specificity is similar to a fallacy of composition, in that you're incorrectly assuming that a part is equivalent to or representative of the whole. Services provided "server side" are a portion of the services that are addressed by the DNS, but equally, "client side" and "peer to peer" services utilize the DNS. RLMcGinley (talk) 19:18, 27 October 2021 (UTC)
How to dumb down the lede
The problem, as I see it, is jargon. "Services" (and, while we're at it, "resources") may make sense to someone who can casually say "and of course, IP addresses of both IPv4 and IPv6 varieties." But what about the non-expert reader? Certainly we can (and do) get into the details in the article, and even in the lede. However, I suggest, the first sentence or two should be very basic. Here are two examples of what I have in mind from elsewhere on the web:
Please review the Wikipedia Manual of Style and WP:NOT. On Wikipedia, we do not oversimplify concepts for consumption by ten-year-old children in the childish manner that you are suggesting. Wikipedia is not a manual, guidebook, or textbook. We have Wikibooks and the Simple English Wikipedia for such situations. The current lead paragraphs are an accurate and lucid explanation of the DNS. --Coolcaesar (talk) 16:44, 27 October 2021 (UTC)
Coolcaesar, WP:NOT says "Texts should be written for everyday readers, not just for academics." It is my opinion that "services" and "other resources" in the first sentence are computer science jargon which, in context, would cause everyday readers to scratch their heads. Is my opinion in error? Butwhatdoiknow (talk) 02:41, 28 October 2021 (UTC)
Yes, your opinion is in error. In the current lede, neither the word "services" nor the phrase "other resources" are jargon. They are being used in their normal, commonly-understood sense. Bill Woodcock (talk) 14:04, 12 November 2021 (UTC)
Bill Woodcock: Granted, my opinion is based on a survey of only 1 everyday reader (me). I wonder, have you asked anyone who is outside of the computer industry to read the sentence and then tell you the in-context meaning of "services" and "other resources"? Butwhatdoiknow (talk) 15:50, 12 November 2021 (UTC)
P.S., make that N=2. When I asked someone with a masters degree in biology (who taught at the university level) what "services" means in this sentence she said "appy things?" And when I asked what "other resources" means she said "I don't know, like ATMs?" Notice that both responses ended with a question mark. Butwhatdoiknow (talk) 22:16, 12 November 2021 (UTC)
Did you give them just one isolated sentence or let them read the full lede? Its definitely not jargon and is the simplest and plainest description for what it provides; the word means the same online or in real life. If someone doesn't understand the word "service" by the end of the first sentence, it is on them to read the rest of the paragraph/article, get a dictionary, or click a wikilink for more context -- Internet is wikilinked in the first paragraph (with 65 uses of the word 'service' and clearly defines it in the lede), as is Services and Directory Service, all giving examples of services, although we could add Web_resource for additional clarity; The section DNS#Function gives multiple service examples. If we are to start over simplifying things, then we'll need to give IP addresses, Devices, and Network Protocols all a more drawn out explanation too. Strangerpete (talk) 14:26, 13 November 2021 (UTC)
I just asked my survey subject about the isolated first sentence. Per MOS:LEADSENTENCE: "The first sentence should tell the nonspecialist reader what or who the subject is, and often when or where. It should be in plain English."
You point out that Services is currently wikilinked in this article. Are you referring to the link in the first sentence? I just put that there. Bill Woodcock complains that this link is "misleadingly-specific" (below at 14:01, 12 November 2021). What is your opinion about this link?
More specifically the policy says "where possible, one that puts the article in context for the nonspecialist. Similarly, if the title is a specialized term (jargon), provide the context as early as possible" and "Try to not overload the first sentence by describing everything notable about the subject. Instead use the first sentence to introduce the topic, and then spread the relevant information out over the entire lead."
I was aware you added the link, but on further inspection I do not think that Service_(systems_architecture) is appropriate as System Architecture is about software development, not end use. On the Internet article, the opening does a decent job of referencing services, followed by examples; we could do something similar here but it doesn't belong in the first sentence. In addition, the infobox lists services, and the section Internet#Applications_and_services, although needing to be expanded, would probably be a better link for 'services' in the first sentence; I'll let discussion decide that though before adding.
I will agree the whole intro could use improvement, and is probably too long, but the first sentence is fine - Using an unrelated GA rated article for example, Brain's lede is "A brain is an organ that serves as the center of the nervous system in all vertebrate and most invertebrate animals." - this does not expand on what the nervous system is, or what vertebrate means, but instead relies on links to add context. I think DNS's opening is no more complex than this, we just need appropriate linking, and follow up.
An additional comparative example, is the twice (2007, 2020) Featured Article article Immune system opening with "The immune system is a network of biological processes that protects an organism from diseases." By comparison to DNS, you are asking to define 'organism' and 'diseases' in the first sentence. The whole intro doesn't even define disease, yet relies on wikilinks. I only use these two examples since they are a subject I am not familiar with (non specialist) and they have received much editing and approval; although I am aware status-quo isn't always the best to maintain, I think it is here. Strangerpete (talk) 17:42, 13 November 2021 (UTC)
I have not communicated effectively if I gave you the impression that my concern would not be met by adding appropriate wikilinks. It seems to me that you have found two good ones: Internet#Applications_and_services for "services" and Web_resource for "resources." Thank you for that. I will add those in a few days unless some other editor objects. Butwhatdoiknow (talk) 21:34, 13 November 2021 (UTC)
Butwhatdoiknow, I'll be a little less blunt, but I agree with Coolcaesar the purpose of Wikipedia is not to assume that readers are "dumb," as you put it, but to assume that they are intellectually curious. We use plain language, and we document the truth. In your attempt to "dumb down" the information, you have stripped the vast majority of the truth from the sentence, leaving only a bare thread of content remaining, not nearly sufficient to summarize the article. You summarize only a tiny portion of the article, whereas the existing text summarizes a more substantial portion of the article and does not pretend to a false completeness or specificity, which your proposed wording does. By analogy, you've replaced a sentence which says that "postal services deliver mail and packages, and in some countries perform banking services," with "postal services deliver letters in white envelopes to people named John." While you may regard it as more accurate, it is actually misleadingly over-specific. RLMcGinley (talk) 18:57, 27 October 2021 (UTC)
RLMcGinley, my concern is that the language in the first sentence is not plain because it is computer industry jargon. What are "services"? How about "other resources?" Maybe you know, but I don't. I can guess (I have a B.S. in computer science that I haven't used in 45 years), but I don't know. Perhaps the samples I gave of "dumber" first sentences are too dumb. Fine, I can live with that. Let's find more accessible language that falls somewhere in-between the current text and the examples. Butwhatdoiknow (talk) 02:41, 28 October 2021 (UTC)
Returning to the meaning of "services" in first sentence
When read in context, "services" refers to distributed Internet services, as explained later on in the article. The point you're missing is that the lead paragraph need not summarize every detail in the entire article, or it will end up duplicating the rest of the article. The lead paragraph merely needs to sketch out the basic outline of the subject matter which is then filled in by the rest of the article. --Coolcaesar (talk) 01:34, 2 November 2021 (UTC)
Thank you, but then the question becomes "what does services mean in the phrase 'distributed Internet services'?" Is it, perhaps, Service (systems architecture) ("software functionalities (such as the retrieval of specified information or the execution of a set of operations)")? Butwhatdoiknow (talk) 16:19, 2 November 2021 (UTC)
I don't understand why you keep advocating for specific, narrow, uses of generally-understood words, when they're presently used in their generally-understood sense. Sure, services as in a system architecture can be a legitimate example of named services, if they are in fact named in the DNS, which presumably only a small minority are. But that's misleadingly-specific, and confuses more than it clarifies. Please stop messing with this sentence unless some consensus is reached that messing with it is likely to improve it. Bill Woodcock (talk) 14:01, 12 November 2021 (UTC)
Internet#Applications_and_services is sufficiently general to at least not be wrong, but Web_resource is not. Neither a geospatial location nor a public key have anything to do with the World Wide Web, for a start. Where is this insistence on false overspecificity coming from? What goal do you hope to achieve by attempting to redefine things as their subsets? It does not improve accuracy or intelligibility. Quite the opposite. Bill Woodcock (talk) 11:15, 14 November 2021 (UTC)
@Bwoodcock Well Web_resource was my suggestion yesterday, in the above-branch of the discussion; and you are right, I had latched on to the 'any identifiable resource' wording, while neglecting the www part, so it is not correct either.
I think 'false overspecificity' is just a by product of trying to pin down a resource (pun intended) that can go into more depth on the definitions without cluttering up the opening, and obviously if someone is unfamiliar with the subject they will have a harder time finding the best definition on their own - If the question is being asked at all, then there is room for improvement, somewhere.
I think it is important to give appropriate wikilinks for services & resources, as pointed out this article doesn't do a super job of defining them (nor should it.) Being naive of all the policies, if someone were to improve a definition in latter part of the article, is linking to that subsection from the opening an acceptable practice? Just curious, although I would personally prefer to find separate articles that have a more introductory-like scope Strangerpete (talk) 15:41, 14 November 2021 (UTC)
@Strangerpete:, I agree in principle, but now that I look at the article overall, the lede seems way, way too long overall, and fairly internally repetitive. I know we've just been talking about the first sentence, but I think quality would improve if the whole thing were trimmed a bit. And no, I don't see any problem with internal links to a part of the article further down. Your proposal seems like a good solution to me. Bill Woodcock (talk) 13:40, 15 November 2021 (UTC)
No, "services" in the first sentence does not refer only to web services. An example of "services" is the mail service (SMTP) for a particular domain as stored in an MX record for that domain. The point being that a client computer wanting to send mail to john@example.com does not know what mail server handles that, so the client queries DNS for a list of available mail servers for example.com and uses one of them (probably the first, falling back to others if there is no response). In principle there could be many other services but browsers (HTTP/HTTPS) have become ubiquitous and malware means sensible people have strict firewalls that permit only well-known traffic and would not pass traffic for a new service that someone dreamed up. Johnuniq (talk) 01:14, 15 November 2021 (UTC)
I believe that a domain may have more than one IP address associated with it, and geoDNS uses geographic location of the caller to provide the IP address of the nearest data centre. Many large organisations have many web servers at each data centre, and the web traffic is balanced my multiple load balancers. Does each of these load balancers have it's own public IP address?, ie does the DNS issue multiple IP addresses for a website even for a single data centre? There is no mention of this practical information in the article.FreeFlow99 (talk) 16:28, 20 November 2021 (UTC)
@FreeFlow99: You've asked a number of questions, each of which has its own (not always simple) answer. I'll take them one-by-one:
...a domain may have more than one IP address associated with it...
Yes, that's correct, and more specifically, a single fully-qualified domain name (FQDN) may have more than one IP address associated with it. That may occur because it has both A and AAAA records (an IPv4 and an IPv6 address), or it may have multiple A and/or AAAA records associated, in which case the client which receives the records might have a choice to make about where to deliver their next packet.
...geoDNS uses geographic location of the caller...
Well... "GeoDNS" is jargon for a whole field of techniques generally referred to as geolocation. It's not a specific technology. There are networks like Akamai, which attempt to use the ECS parameter of a query, or failing that, the origin IP address of the transit interface of the recursive resolver which serviced the query, as one component in their decision about what A and/or AAAA record(s) to hand back in response to a query. They may be looking at the originating Autonomous System, at their return paths, at someone's guess as to the geographic location of the IP address, or at round-trip response times for that address or others in its BGP-advertised subnet. Or other factors, those are just the first few that spring to mind.
...to provide the IP address of the nearest data centre...
Well, first of all, as you point out later, datacenters don't have IP addresses, individual services have IP addresses. So, if we amend that to:
...to provide an IP address of a service hosted in the nearest data centre...
...then the answer would be "Well, sometimes they try to; sometimes not." As I said, there are many different factors that weigh into a decision on where to try to influence client traffic to route to. Even if one had an unambiguous geolocation for a specific ECS-supplied IP address, that still doesn't tell you what their path to a datacenter (of known location) is, and the geographically nearest may not be the topologically nearest, which is what matters. Which is why sensible networks use anycast rather than trying to make geolocation not fall on its ass too badly, since anycast gets you directly to the topologically nearest instance, without all of this room for error.
Many large organisations have many web servers at each data centre...
Yes, true of small organizations as well. Beneficial redundancy is good.
...web traffic is balanced my multiple load balancers.
"Load balancers" were something hucksters sold to clueless enterprise network buyers back in the 1990s, they've never been a thing in serious networks. They can be replaced with a patch-cord without loss in functionality and with considerable gain in MTBF. So I'll amend your next question to "servers" so we can dive back in:
Does each server have it's own public IP address?
Typically no. Typically each server has its own private IP address (whether that's "private" in the RFC1918 sense, or "private" in the "not advertised to the public in the DNS" sense) so that it can be managed, its cache stuffed, etc. But on the public-facing side, each service has exactly one IPv4 and one IPv6 address. There's no reason to have more than one address per service, it just complicates things without adding any value. And there's no reason for the same service on different servers to have different addresses, that again just complicates things without adding value.
...does the DNS issue multiple IP addresses for a website...
Yes, often hundreds, perhaps thousands. Every tracking bug, advertisement, etc., is going to have its own IP address, since they're all going different places. But I don't think that's what you meant when you asked the question.
...even for a single data centre?
Well, many of those services may be physically hosted in many of the same datacenters, but each is independent of the others, so that's just a coincidence. If what you mean to ask is:
Do instances of a service hosted on different servers within the same datacenter have different IP addresses?
...then the answer is no, not in a competently-run network that's functioning properly.
There is no mention of this practical information in the article.
Correct, because none of it has to do with the domain name system, it has to do with IP address assignment. The DNS is just how those IP addresses are communicated to users. The Anycast article would be a good reference, if you feel like pursuing this further. I'd be happy to try to answer any further questions, though, here or there. Bill Woodcock (talk) 17:24, 20 November 2021 (UTC)
Thanks Bill! Thanks for taking the time to constructively reconstruct my questions and answer them; that's very helpful.
Most of that sounds great, but I'm still puzzled. I worked in a .com a few years ago and it was putting in a load balancer to distribute traffic to a pair of IBM Data Power web appliances (which then go to a server farm if they don't have the appropriate web page, so that a server can create the page). I think in the old setup they used one or more load balancers to distribute traffic to 80 web servers. I read an article today about an Application Gateway Load Balancing Proxy FireWall that also provides session management, authenticating, and rate limiting. In the absence of a load balancer(s), how would traffic be distributed to web appliances and servers; by using DNS servers to serve up public IP addresses for the servers/services in a randomly distributed fashion? Feel free to divide and conquer the above questions. FreeFlow99 (talk) 17:50, 20 November 2021 (UTC)
The normal way to do it is to use anycast to get your traffic to both your DNS and your content. All your DNS servers serve the same consistent A and AAAA answer for each service, and each instance of each service has one consistent IPv4 address and one consistent IPv6 address everywhere. If the services support redirection, like web servers, they can choose to redirect long-TCP-session users to a unique address, and if a server becomes overloaded, it sends a BGP withdrawal to its adjacent router, removing itself from the pool that accept new connections. Load balancing is a function best done on the servers themselves, not by an extraneous middlebox, which just creates an additional serial point of failure. Which is great for people selling additional points of failure, but not so great for people trying to keep services running. Any large network then has an overlay of proprietary fine-tuning knobs, and DDoS countermeasures, and "traffic engineering," but all that's useless if you don't build a strong foundation. Bill Woodcock (talk) 21:04, 20 November 2021 (UTC)
We should define "relevant" first - of the lump of RFCs you added (and besides the duplicates, I do see your point) more than a few are obsolete, drafts, historic, or experimental in the 90s, and a couple not even related (1750, 2133.) We clearly cannot show them all, and besides being a wall of numbers it isn't helpful to anyone to understand the protocol. I'd argue anything that isn't a standard or proposed standard, probably doesn't belong in the infobox.
I think one step to make it more navigable could be to split certain classes of RFCs into separate fields, such as Best Common Practices, which could be more helpful to a reader. Or separating core specification from extensions and experiments. Strangerpete (talk) 01:55, 29 November 2021 (UTC)
I agree with all that. I hadn't yet made any attempt to differentiate them; it was as much to make a point as anything else. My opinion is that an infobox isn't appropriate here, in that as-is it's overly reductive, and if it were fixed to be more inclusive, it would be in danger of becoming a catalog of the rest of the article, duplicative of the table of contents or index of RFCs. So, I guess my point is that I think that we should either remove the infobox, or put a heck of a lot more thought into it than has happened thus far. Bill Woodcock (talk) 09:41, 29 November 2021 (UTC)
Quibble about the the supposed inadequacy of the phonebook analogy.
The article states "The key functionality of the DNS exploited here is that different users can simultaneously receive different translations for the same domain name, a key point of divergence from a traditional phone-book view of the DNS." I don't know if its just that everyone is too young to remember how phones books worked, but that's exactly how phone books worked. If you looked up John Smith in a New York phone book, it would tell you the name the John Smith that lives in that area. It would be a different phone number than the one given for John Smith in California. Businesses worked the same way. If you wanted to call up IBM, you were going to get the phone number for the nearest IBM office. Do people think that phone books contained literally every single phone number and that they were all identical?
Geo-location discriminant recursive resolution for example (something that comes to my mind). If you're resolving big-corp-domain.com around DE or NL, you'll unlikely gonna get the same result around the US or CA and JP or CN. --WikiLinuz {talk} 🍁09:39, 25 May 2022 (UTC)
Also, DNS is a complex mechanism. It could be deduced into a "phone book" in a straightforward reductionist approach, but much more things get involved in reality. --WikiLinuz {talk} 🍁09:43, 25 May 2022 (UTC)
'Decentralized'
In the first sentence of the article:
"The Domain Name System (DNS) is a hierarchical decentralized naming system"
refers to DNS as decentralized. In the rest of the article, the word 'distributed' is used.
Is there a source for the use of 'decentralized' here?
Can the word 'decentralized' be omitted, or is it bound to hierarchical?
Should it also be replaced with 'distributed' here?
I was tempted to simply follow the suggestion and replace decentralized with distributed. But the followup sentence already describes the directory service as distributed. It appears that both are correct characterizations, taking the meaning of decentralized in its dictionary sense. As such it is probably a lot more meaningful to a general audience than distributed, which is a highly technical term. I think, I prefer to keep it as written, with the exception of adding a comma or and after hierarchical to separate the association of those characterizations. Kbrose (talk) 16:05, 4 February 2019 (UTC)
If the convention is to assume users will look this up in a dictionary then that is fine. In the literature (and standards?) there often is a difference [1]131.174.85.103 (talk) 16:46, 4 February 2019 (UTC) R.
This reference makes the case stronger for also retaining the decentralized description as this meshes with how the DNS hierarchy works. ~Kvng (talk) 15:00, 12 February 2019 (UTC)
I replaced decentralized with distributed before noticing this existing discussion. Decentralized seems obviously wrong for a hierarchy with a central root, but I'm open to the idea that my definition of decentralized is not the same as that of a general audience, and won't be bothered if there's consensus for a revert. DefaultFree (talk) 02:15, 27 October 2022 (UTC)
I think what's referred to as "the HOSTS.TXT file" should be changed to "the hosts file", considering it's most often /etc/hosts on unix-like OSes, and [last time I checked] doesn't even have the .txt extension on Win32. --Midg3t 00:33, 12 Mar 2005 (UTC) — Preceding unsigned comment added by Tedp (talk • contribs) 00:33, 12 March 2005 (UTC)
It was called "HOSTS.TXT" in the pre-DNS days 25 years ago. Samboy 22:12, 18 Mar 2005 (UTC)
And that bit is specific: the file that was retrieved was named HOSTS.TXT. Of course, after it was retrieved, it was renamed to whatever the local operating system required. — mendel☎ 00:56, Jun 16, 2005 (UTC)
Removal is appropriate, IMO -- Wikipedia is not a repository of links. If there's useful information at those sites that is relevant to the article but is not already mentioned, it should be included in the article — mendel☎ 00:55, Jun 16, 2005 (UTC)
Don't Merge
Domain Name System is a long article which should discuss technical aspects of the system of domain names.
Domain Name should discuss only the names themselves, including the domain name market, daytrading domain names, domain name auctions, registrars snapping up expired domains, domain name tasting, domain name drops, and other aspects of this industry. — Preceding unsigned comment added by Sokool (talk • contribs) 15:58, 21 April 2006 (UTC)
Contradicts "Canonical Name" on internationalization. Secondary and slave.
http://wiki.riteme.site/wiki/Canonical_name states that:
The maximum permitted length of an FQDN is 255 bytes, with an additional restriction to 63 bytes for each label within the domain name. The syntax of domain names is discussed in various RFCs — RFC 1035, RFC 1123 and RFC 2181. Any binary string can be used as the label of any resource record; a common misconception is that names are limited to a subset of ASCII characters.
But "DNS" article states that domain names are limited to a subset of ASCII.
One more issue is that "secondary or slave name servers" expression is used. BIND manual states that "The other authoritative servers, the slave servers (also known as secondary servers)", which looks like secondary is a mere alias for slave. If I'm assuming wrongly, a clarification on the difference in the article would be helpful. — Preceding unsigned comment added by 60.234.133.143 (talk) 14:45, 21 July 2006 (UTC)
Is there some reason why this is not mentioned in this article? Are there certain types of records that are not included in this article for a specific reason?
Thanks in advance for any input. — Preceding unsigned comment added by Brian Gragg (talk • contribs) 20:53, 18 August 2017 (UTC)

 Done, thank you very much!
Done, thank you very much!  ~ ToBeFree (talk) 20:03, 18 July 2021 (UTC)
~ ToBeFree (talk) 20:03, 18 July 2021 (UTC)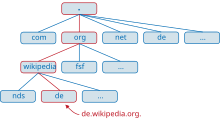



 Not done for now: please establish a consensus for this alteration before using the
Not done for now: please establish a consensus for this alteration before using the