Welcome to the Wikipedia Mathematics Reference Desk Archives
The page you are currently viewing is an archive page. While you can leave answers for any questions shown below, please ask new questions on one of the current reference desk pages.
but was met with deafening silence. Does anyone here do enough mathematical physics to be able to help out? -- ToE04:01, 26 January 2012 (UTC) Sorry for the cross post, but this appears to be a well posed, serious question that was beyond the capabilities of the RD/S regulars.[reply]
I just undid an edit which removed the above suggestion as possible spam. The OP IP's edit history suggests that it was a good faith suggestion of an alternate resource. I'm not familiar with that website, but see that replacing the URL's "math" with "physics" yields a board which might be even more helpful. -- ToE00:13, 31 January 2012 (UTC)[reply]
Harmonic Sequences and Other Sequences (Mathematics)
Hi, I really need to know how to solve a harmonic sequence in math. I know that there is no general formula in a harmonic sequence, but I'm still confused about it.
I'm trying my best to understand it, specially on how to solve it. But the problem is I don't know how. Can you please help me? Please show me examples, explain how to solve it, give it's meaning and I would be very happy if you will provide more information about it.
How can Harmonic Sequences and Other Sequences differ from each other? Is it about the operations I will use? Like if I will multiply it or divide it?
Please teach me in solving other sequences. I'm worried, because I have to report this topic next week. Please help me, and thank you. — Preceding unsigned comment added by NovelleJohnson (talk • contribs) 12:40, 26 January 2012 (UTC)[reply]
I came across an interesting observation and I was wondering if there is a name for the trick behind it or if it was well known or occurred somewhere else. It was that whilst the government statistics said pensioners were getting richer in fact individually they got poorer. The way it worked was that new pensioners were richer and old pensioners dying off were poorer. So both sides of the argument were in fact correct. Anyone come across this effect? Dmcq (talk) 18:11, 26 January 2012 (UTC)[reply]
I can't easily tell if it's an exact match, but this is closely related to Simpson's paradox. Basically, the idea is that two opposite (seemingly contradictory) relationships can be seen in the same data, depending on how they are grouped. The article is quite nice, including an illuminating figure and several famous real-world examples. SemanticMantis (talk) 18:53, 26 January 2012 (UTC)[reply]
Thanks for those suggestions. The bit in survivorship bias about results being reported only for companies which have survived sounds very similar I think. It sounds quite a difficult problem to avoid in fact. Dmcq (talk) 00:46, 27 January 2012 (UTC)[reply]
For another example, I believe there was a time where the average size of GM vehicles was going up, while the individual model size was going down. This was because they would introduce new full-sized vehicles while downsizing the existing fleet. Note that "adding new data points" applies in both cases, whether new pensioners or new full-sized models. StuRat (talk) 00:01, 28 January 2012 (UTC)[reply]
Yes that's exactly the same, I wonder, do you know how anyone noticed that was happening or why were they doing it thanks? When you phrase it as 'adding new datapoints' it certainly makes it obvious that the underlying problem is probably quite common even if the consequences aren't always so strange. Dmcq (talk)
They did it because people like to feel like they are getting "more car for less money". So, if they downsize a full-size model to be mid-sized, people still think of it as a full-sized model for some time, and are thus willing to pay more. Of course, this would inevitably result in nothing but sub-compacts, unless they also added new full-sized models to the line. But, after doing this for a few years, people figured it out, it no longer became an effective strategy, and they stopped. The most extreme example of this downsizing strategy is the Hummer H1 (86.5 inch width), Hummer H2 (81.2 inch width), and Hummer H3 (74.7 inch width). GM had previously tried a strategy of introducing new models at the small end of each make, with less success, like the Cadillac Cimarron. StuRat (talk) 20:29, 29 January 2012 (UTC)[reply]
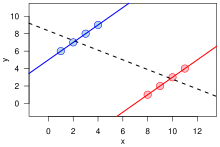
After some thought, I'm sure now that the pensioner case is a textbook example of Simpson's paradox. Look at this graph from our article. Consider red to be one pensioner, blue another. Consider the horizontal axis to be time, and reverse it (read it right to left), and let the vertical axis represent net worth. Interpreted this way, it illustrates how it can be that each individual's net worth goes down over time, while the total group mean goes up. So yes, the phenomenon does have a name, and it comes up fairly often. Our article indicates that it is not well-known, but experts have recommended that we raise awareness :) SemanticMantis (talk) 17:41, 28 January 2012 (UTC)[reply]
Yes I agree it is an example of Simpson's paradox okay, that graph is practically exactly what is happening with the pensioners. It would be nice if the article had a continuous case as in the GM models or pensioners if there's some good citation, it just has a one liner at the moment saying it applies in such cases plus the graph at the head and I completely missed the references when skimming through before. Dmcq (talk) 02:02, 30 January 2012 (UTC)[reply]
Let's say that you have m groups of people: G1, …, Gm. There are n rooms, say R1, …, Rn. We ask one person from each group to (randomly) go into one of the rooms, so that no person from the same group is in the same room. Assume that each room has exactly one person from each group. (I think this means |G1| = … = |Gm| = n.) Each room now has m people in it: one from each group. Everyone goes back to their groups. Again, we ask one person from each group to (randomly) go into one of the rooms, so that no person from the same group is in the same room. What is the probability that at least two of the people together in room one after the first sort will find themselves together in another room after the second sort? — Fly by Night(talk)18:42, 26 January 2012 (UTC)[reply]
You can check that if , it's guaranteed. Otherwise, the idea is that it's easier to count the probability of it not happening. If you take the first person from the first room, the probability that the second person from their new room is not the second person from their old room is . Similarly for every other person from their new room. So the odds that they see no one familiar is . Now, assuming the first person saw no one familiar, the second person from the first room is guaranteed not to see the first person. But they still need to perform the above calculation for the third and on person of their new room. But now the probability that the third person of their new room is not the third person from their old room is , since one wrong person from the third group has already been spent on the first person's room. Similarly for the rest of the people in their new room. Following this pattern, the final formula is .--195.37.234.132 (talk) 20:57, 26 January 2012 (UTC)[reply]
Thank you very much for such a detailed answer. I appreciate you taking the time to help me. Reading your reasoning, it worries me that you say things like "If you take the first person from the first room, the probability that the second person from their new room is not the second person from their old room…" Does that mean that the order in which people enter the room matters? The order in which they enter the room is unimportant. I suspect that this is indeed the case with your expression, but I would just like you to confirm that that is the case. I look forward to hearing your thoughts. Thanks again! — Fly by Night(talk)21:38, 27 January 2012 (UTC)[reply]
No, it doesn't matter. When you want a bunch of events to all happen (in this case, we want everyone from the first room to not see anyone familiar), it's common to think about them one at a time, and that tends to color the language we use to talk about it. But as you say, the order is unimportant.--195.37.234.132 (talk) 22:29, 27 January 2012 (UTC)[reply]
Not sure what the question is; the Alpha page gives an expression as a polynomial in p, are you having trouble evaluating the polynomial? Are you stuck on how you would get the polynomial from the summation? The summation obviously diverges for z=2, so the value of the of Φ is defined via analytic continuation; are you confused about that?--RDBury (talk) 10:32, 28 January 2012 (UTC)[reply]
Also, though it's not stated in the article, it's obvious from the definition (see geometric series) that
Apply the identity with with s=0 to get
Apply the identity with with s=-1 to get
Plugging z=2 in gives
which agrees with Alpha's expression once you simplify and replace a with p.
Another approach is to multiply by 1−z and combine terms to evaluate the sum:
which is the expression obtained before. This is directly from the definition except for the grinding noises. This only works for |z|<1 but you can extend it to z=2 by analytic continuation.--RDBury (talk) 23:23, 28 January 2012 (UTC)[reply]