
Ordinary least squares

| Part of a series on |
| Regression analysis |
|---|
| Models |
| Estimation |
| Background |
In statistics, ordinary least squares (OLS) is a type of linear least squares method for choosing the unknown parameters in a linear regression model (with fixed level-one[clarification needed] effects of a linear function of a set of explanatory variables) by the principle of least squares: minimizing the sum of the squares of the differences between the observed dependent variable (values of the variable being observed) in the input dataset and the output of the (linear) function of the independent variable. Some sources consider OLS to be linear regression.[1]
Geometrically, this is seen as the sum of the squared distances, parallel to the axis of the dependent variable, between each data point in the set and the corresponding point on the regression surface—the smaller the differences, the better the model fits the data. The resulting estimator can be expressed by a simple formula, especially in the case of a simple linear regression, in which there is a single regressor on the right side of the regression equation.
The OLS estimator is consistent for the level-one fixed effects when the regressors are exogenous and forms perfect colinearity (rank condition), consistent for the variance estimate of the residuals when regressors have finite fourth moments[2] and—by the Gauss–Markov theorem—optimal in the class of linear unbiased estimators when the errors are homoscedastic and serially uncorrelated. Under these conditions, the method of OLS provides minimum-variance mean-unbiased estimation when the errors have finite variances. Under the additional assumption that the errors are normally distributed with zero mean, OLS is the maximum likelihood estimator that outperforms any non-linear unbiased estimator.
Linear model
[edit]Suppose the data consists of observations . Each observation includes a scalar response and a column vector of parameters (regressors), i.e., . In a linear regression model, the response variable, , is a linear function of the regressors:






![{\displaystyle \mathbf {x} _{i}=\left[x_{i1},x_{i2},\dots ,x_{ip}\right]^{\operatorname {T} }}](https://wikimedia.riteme.site/api/rest_v1/media/math/render/svg/3278872b5bdb53e6af3474d92e9926c0238e8935)

or in vector form,

where , as introduced previously, is a column vector of the -th observation of all the explanatory variables; is a vector of unknown parameters; and the scalar represents unobserved random variables (errors) of the -th observation. accounts for the influences upon the responses from sources other than the explanatory variables . This model can also be written in matrix notation as




where and are vectors of the response variables and the errors of the observations, and is an matrix of regressors, also sometimes called the design matrix, whose row is and contains the -th observations on all the explanatory variables.






Typically, a constant term is included in the set of regressors , say, by taking for all . The coefficient corresponding to this regressor is called the intercept. Without the intercept, the fitted line is forced to cross the origin when .




Regressors do not have to be independent for estimation to be consistent e.g. they may be non-linearly dependent. Short of perfect multicollinearity, parameter estimates may still be consistent; however, as multicollinearity rises the standard error around such estimates increases and reduces the precision of such estimates. When there is perfect multicollinearity, it is no longer possible to obtain unique estimates for the coefficients to the related regressors; estimation for these parameters cannot converge (thus, it cannot be consistent).
As a concrete example where regressors are non-linearly dependent yet estimation may still be consistent, we might suspect the response depends linearly both on a value and its square; in which case we would include one regressor whose value is just the square of another regressor. In that case, the model would be quadratic in the second regressor, but none-the-less is still considered a linear model because the model is still linear in the parameters ().
Matrix/vector formulation
[edit]Consider an overdetermined system

of linear equations in unknown coefficients, , with . This can be written in matrix form as



where

(Note: for a linear model as above, not all elements in contains information on the data points. The first column is populated with ones, . Only the other columns contain actual data. So here is equal to the number of regressors plus one).

Such a system usually has no exact solution, so the goal is instead to find the coefficients which fit the equations "best", in the sense of solving the quadratic minimization problem

where the objective function is given by


A justification for choosing this criterion is given in Properties below. This minimization problem has a unique solution, provided that the columns of the matrix are linearly independent, given by solving the so-called normal equations:

The matrix is known as the normal matrix or Gram matrix and the matrix is known as the moment matrix of regressand by regressors.[3] Finally, is the coefficient vector of the least-squares hyperplane, expressed as




or

Estimation
[edit]Suppose b is a "candidate" value for the parameter vector β. The quantity yi − xiTb, called the residual for the i-th observation, measures the vertical distance between the data point (xi, yi) and the hyperplane y = xTb, and thus assesses the degree of fit between the actual data and the model. The sum of squared residuals (SSR) (also called the error sum of squares (ESS) or residual sum of squares (RSS))[4] is a measure of the overall model fit:

where T denotes the matrix transpose, and the rows of X, denoting the values of all the independent variables associated with a particular value of the dependent variable, are Xi = xiT. The value of b which minimizes this sum is called the OLS estimator for β. The function S(b) is quadratic in b with positive-definite Hessian, and therefore this function possesses a unique global minimum at , which can be given by the explicit formula[5][proof]


The product N = XT X is a Gram matrix, and its inverse, Q = N−1, is the cofactor matrix of β,[6][7][8] closely related to its covariance matrix, Cβ. The matrix (XT X)−1 XT = Q XT is called the Moore–Penrose pseudoinverse matrix of X. This formulation highlights the point that estimation can be carried out if, and only if, there is no perfect multicollinearity between the explanatory variables (which would cause the Gram matrix to have no inverse).
Prediction
[edit]After we have estimated β, the fitted values (or predicted values) from the regression will be

where P = X(XTX)−1XT is the projection matrix onto the space V spanned by the columns of X. This matrix P is also sometimes called the hat matrix because it "puts a hat" onto the variable y. Another matrix, closely related to P is the annihilator matrix M = In − P; this is a projection matrix onto the space orthogonal to V. Both matrices P and M are symmetric and idempotent (meaning that P2 = P and M2 = M), and relate to the data matrix X via identities PX = X and MX = 0.[9] Matrix M creates the residuals from the regression:

The variances of the predicted values are found in the main diagonal of the variance-covariance matrix of predicted values:


were P is the projection matrix and s2 is the sample variance.[10] The full matrix is very large; its diagonal elements can be calculated individually as:

where Xi is the i-th row of matrix X.
Sample statistics
[edit]Using these residuals we can estimate the sample variance s2 using the reduced chi-squared statistic:

The denominator, n−p, is the statistical degrees of freedom. The first quantity, s2, is the OLS estimate for σ2, whereas the second, , is the MLE estimate for σ2. The two estimators are quite similar in large samples; the first estimator is always unbiased, while the second estimator is biased but has a smaller mean squared error. In practice s2 is used more often, since it is more convenient for the hypothesis testing. The square root of s2 is called the regression standard error,[11] standard error of the regression,[12][13] or standard error of the equation.[9]

It is common to assess the goodness-of-fit of the OLS regression by comparing how much the initial variation in the sample can be reduced by regressing onto X. The coefficient of determination R2 is defined as a ratio of "explained" variance to the "total" variance of the dependent variable y, in the cases where the regression sum of squares equals the sum of squares of residuals:[14]

where TSS is the total sum of squares for the dependent variable, , and is an n×n matrix of ones. ( is a centering matrix which is equivalent to regression on a constant; it simply subtracts the mean from a variable.) In order for R2 to be meaningful, the matrix X of data on regressors must contain a column vector of ones to represent the constant whose coefficient is the regression intercept. In that case, R2 will always be a number between 0 and 1, with values close to 1 indicating a good degree of fit.



Simple linear regression model
[edit]If the data matrix X contains only two variables, a constant and a scalar regressor xi, then this is called the "simple regression model". This case is often considered in the beginner statistics classes, as it provides much simpler formulas even suitable for manual calculation. The parameters are commonly denoted as (α, β):

The least squares estimates in this case are given by simple formulas
![{\displaystyle {\begin{aligned}{\widehat {\beta }}&={\frac {\sum _{i=1}^{n}{(x_{i}-{\bar {x}})(y_{i}-{\bar {y}})}}{\sum _{i=1}^{n}{(x_{i}-{\bar {x}})^{2}}}}\\[2pt]{\widehat {\alpha }}&={\bar {y}}-{\widehat {\beta }}\,{\bar {x}}\ ,\end{aligned}}}](https://wikimedia.riteme.site/api/rest_v1/media/math/render/svg/932c6407f7ceba533fef69961fe504fc3b565e1e)
Alternative derivations
[edit]In the previous section the least squares estimator was obtained as a value that minimizes the sum of squared residuals of the model. However it is also possible to derive the same estimator from other approaches. In all cases the formula for OLS estimator remains the same: ^β = (XTX)−1XTy; the only difference is in how we interpret this result.

Projection
[edit]


This section may need to be cleaned up. It has been merged from Linear least squares. |
For mathematicians, OLS is an approximate solution to an overdetermined system of linear equations Xβ ≈ y, where β is the unknown. Assuming the system cannot be solved exactly (the number of equations n is much larger than the number of unknowns p), we are looking for a solution that could provide the smallest discrepancy between the right- and left- hand sides. In other words, we are looking for the solution that satisfies

where ‖·‖ is the standard L2 norm in the n-dimensional Euclidean space Rn. The predicted quantity Xβ is just a certain linear combination of the vectors of regressors. Thus, the residual vector y − Xβ will have the smallest length when y is projected orthogonally onto the linear subspace spanned by the columns of X. The OLS estimator in this case can be interpreted as the coefficients of vector decomposition of ^y = Py along the basis of X.
In other words, the gradient equations at the minimum can be written as:

A geometrical interpretation of these equations is that the vector of residuals, is orthogonal to the column space of X, since the dot product is equal to zero for any conformal vector, v. This means that is the shortest of all possible vectors , that is, the variance of the residuals is the minimum possible. This is illustrated at the right.




Introducing and a matrix K with the assumption that a matrix is non-singular and KT X = 0 (cf. Orthogonal projections), the residual vector should satisfy the following equation:

![{\displaystyle [\mathbf {X} \ \mathbf {K} ]}](https://wikimedia.riteme.site/api/rest_v1/media/math/render/svg/2ac770308f79814997ffbdfd971621c67b76aef6)

The equation and solution of linear least squares are thus described as follows:

Another way of looking at it is to consider the regression line to be a weighted average of the lines passing through the combination of any two points in the dataset.[15] Although this way of calculation is more computationally expensive, it provides a better intuition on OLS.
Maximum likelihood
[edit]The OLS estimator is identical to the maximum likelihood estimator (MLE) under the normality assumption for the error terms.[16][proof] This normality assumption has historical importance, as it provided the basis for the early work in linear regression analysis by Yule and Pearson.[citation needed] From the properties of MLE, we can infer that the OLS estimator is asymptotically efficient (in the sense of attaining the Cramér–Rao bound for variance) if the normality assumption is satisfied.[17]
Generalized method of moments
[edit]In iid case the OLS estimator can also be viewed as a GMM estimator arising from the moment conditions
![{\displaystyle \mathrm {E} {\big [}\,x_{i}\left(y_{i}-x_{i}^{\operatorname {T} }\beta \right)\,{\big ]}=0.}](https://wikimedia.riteme.site/api/rest_v1/media/math/render/svg/1d7894c141dad7e6dae3aed8bb708aada174daf2)
These moment conditions state that the regressors should be uncorrelated with the errors. Since xi is a p-vector, the number of moment conditions is equal to the dimension of the parameter vector β, and thus the system is exactly identified. This is the so-called classical GMM case, when the estimator does not depend on the choice of the weighting matrix.
Note that the original strict exogeneity assumption E[εi | xi] = 0 implies a far richer set of moment conditions than stated above. In particular, this assumption implies that for any vector-function ƒ, the moment condition E[ƒ(xi)·εi] = 0 will hold. However it can be shown using the Gauss–Markov theorem that the optimal choice of function ƒ is to take ƒ(x) = x, which results in the moment equation posted above.
Properties
[edit]Assumptions
[edit]There are several different frameworks in which the linear regression model can be cast in order to make the OLS technique applicable. Each of these settings produces the same formulas and same results. The only difference is the interpretation and the assumptions which have to be imposed in order for the method to give meaningful results. The choice of the applicable framework depends mostly on the nature of data in hand, and on the inference task which has to be performed.
One of the lines of difference in interpretation is whether to treat the regressors as random variables, or as predefined constants. In the first case (random design) the regressors xi are random and sampled together with the yi's from some population, as in an observational study. This approach allows for more natural study of the asymptotic properties of the estimators. In the other interpretation (fixed design), the regressors X are treated as known constants set by a design, and y is sampled conditionally on the values of X as in an experiment. For practical purposes, this distinction is often unimportant, since estimation and inference is carried out while conditioning on X. All results stated in this article are within the random design framework.
Classical linear regression model
[edit]The classical model focuses on the "finite sample" estimation and inference, meaning that the number of observations n is fixed. This contrasts with the other approaches, which study the asymptotic behavior of OLS, and in which the behavior at a large number of samples is studied.
- Correct specification. The linear functional form must coincide with the form of the actual data-generating process.
- Strict exogeneity. The errors in the regression should have conditional mean zero:[18] The immediate consequence of the exogeneity assumption is that the errors have mean zero: E[ε] = 0 (for the law of total expectation), and that the regressors are uncorrelated with the errors: E[XTε] = 0. The exogeneity assumption is critical for the OLS theory. If it holds then the regressor variables are called exogenous. If it does not, then those regressors that are correlated with the error term are called endogenous,[19] and the OLS estimator becomes biased. In such case the method of instrumental variables may be used to carry out inference.
- No linear dependence. The regressors in X must all be linearly independent. Mathematically, this means that the matrix X must have full column rank almost surely:[20] Usually, it is also assumed that the regressors have finite moments up to at least the second moment. Then the matrix Qxx = E[XTX / n] is finite and positive semi-definite. When this assumption is violated the regressors are called linearly dependent or perfectly multicollinear. In such case the value of the regression coefficient β cannot be learned, although prediction of y values is still possible for new values of the regressors that lie in the same linearly dependent subspace.
- Spherical errors:[20] where In is the identity matrix in dimension n, and σ2 is a parameter which determines the variance of each observation. This σ2 is considered a nuisance parameter in the model, although usually it is also estimated. If this assumption is violated then the OLS estimates are still valid, but no longer efficient. It is customary to split this assumption into two parts:
- Homoscedasticity: E[ εi2 | X ] = σ2, which means that the error term has the same variance σ2 in each observation. When this requirement is violated this is called heteroscedasticity, in such case a more efficient estimator would be weighted least squares. If the errors have infinite variance then the OLS estimates will also have infinite variance (although by the law of large numbers they will nonetheless tend toward the true values so long as the errors have zero mean). In this case, robust estimation techniques are recommended.
- No autocorrelation: the errors are uncorrelated between observations: E[ εiεj | X ] = 0 for i ≠ j. This assumption may be violated in the context of time series data, panel data, cluster samples, hierarchical data, repeated measures data, longitudinal data, and other data with dependencies. In such cases generalized least squares provides a better alternative than the OLS. Another expression for autocorrelation is serial correlation.
- Normality. It is sometimes additionally assumed that the errors have normal distribution conditional on the regressors:[21]This assumption is not needed for the validity of the OLS method, although certain additional finite-sample properties can be established in case when it does (especially in the area of hypotheses testing). Also when the errors are normal, the OLS estimator is equivalent to the maximum likelihood estimator (MLE), and therefore it is asymptotically efficient in the class of all regular estimators. Importantly, the normality assumption applies only to the error terms; contrary to a popular misconception, the response (dependent) variable is not required to be normally distributed.[22]
![{\displaystyle \operatorname {E} [\,\varepsilon \mid X\,]=0.}](https://wikimedia.riteme.site/api/rest_v1/media/math/render/svg/dcdfa07f07180573874658708bc2a889d5416199)
![{\displaystyle \Pr \!{\big [}\,\operatorname {rank} (X)=p\,{\big ]}=1.}](https://wikimedia.riteme.site/api/rest_v1/media/math/render/svg/6a11be3b89ce51c6441155fddbe512a991132fbf)
![{\displaystyle \operatorname {Var} [\,\varepsilon \mid X\,]=\sigma ^{2}I_{n},}](https://wikimedia.riteme.site/api/rest_v1/media/math/render/svg/0df70427bd7e0b69175caf9150b2d465dd152474)

Independent and identically distributed (iid)
[edit]In some applications, especially with cross-sectional data, an additional assumption is imposed — that all observations are independent and identically distributed. This means that all observations are taken from a random sample which makes all the assumptions listed earlier simpler and easier to interpret. Also this framework allows one to state asymptotic results (as the sample size n → ∞), which are understood as a theoretical possibility of fetching new independent observations from the data generating process. The list of assumptions in this case is:
- iid observations: (xi, yi) is independent from, and has the same distribution as, (xj, yj) for all i ≠ j;
- no perfect multicollinearity: Qxx = E[ xi xiT ] is a positive-definite matrix;
- exogeneity: E[ εi | xi ] = 0;
- homoscedasticity: Var[ εi | xi ] = σ2.
Time series model
[edit]- The stochastic process {xi, yi} is stationary and ergodic; if {xi, yi} is nonstationary, OLS results are often spurious unless {xi, yi} is co-integrating.[23]
- The regressors are predetermined: E[xiεi] = 0 for all i = 1, ..., n;
- The p×p matrix Qxx = E[ xi xiT ] is of full rank, and hence positive-definite;
- {xiεi} is a martingale difference sequence, with a finite matrix of second moments Qxxε² = E[ εi2xi xiT ].
Finite sample properties
[edit]First of all, under the strict exogeneity assumption the OLS estimators and s2 are unbiased, meaning that their expected values coincide with the true values of the parameters:[24][proof]

![{\displaystyle \operatorname {E} [\,{\hat {\beta }}\mid X\,]=\beta ,\quad \operatorname {E} [\,s^{2}\mid X\,]=\sigma ^{2}.}](https://wikimedia.riteme.site/api/rest_v1/media/math/render/svg/67bc2fd0f90c46da207712893fdcea01e729026c)
If the strict exogeneity does not hold (as is the case with many time series models, where exogeneity is assumed only with respect to the past shocks but not the future ones), then these estimators will be biased in finite samples.
The variance-covariance matrix (or simply covariance matrix) of is equal to[25]
![{\displaystyle \operatorname {Var} [\,{\hat {\beta }}\mid X\,]=\sigma ^{2}\left(X^{\operatorname {T} }X\right)^{-1}=\sigma ^{2}Q.}](https://wikimedia.riteme.site/api/rest_v1/media/math/render/svg/08f6cb596d94073731ee47f4a2571dbbfc1d214a)
In particular, the standard error of each coefficient is equal to square root of the j-th diagonal element of this matrix. The estimate of this standard error is obtained by replacing the unknown quantity σ2 with its estimate s2. Thus,


It can also be easily shown that the estimator is uncorrelated with the residuals from the model:[25]
![{\displaystyle \operatorname {Cov} [\,{\hat {\beta }},{\hat {\varepsilon }}\mid X\,]=0.}](https://wikimedia.riteme.site/api/rest_v1/media/math/render/svg/664c1a5e37957a1aa2ae381b9bcb07350c2c816c)
The Gauss–Markov theorem states that under the spherical errors assumption (that is, the errors should be uncorrelated and homoscedastic) the estimator is efficient in the class of linear unbiased estimators. This is called the best linear unbiased estimator (BLUE). Efficiency should be understood as if we were to find some other estimator which would be linear in y and unbiased, then [25]

![{\displaystyle \operatorname {Var} [\,{\tilde {\beta }}\mid X\,]-\operatorname {Var} [\,{\hat {\beta }}\mid X\,]\geq 0}](https://wikimedia.riteme.site/api/rest_v1/media/math/render/svg/53796c9205889cc4d675b9749a58eb97fcd998f1)
in the sense that this is a nonnegative-definite matrix. This theorem establishes optimality only in the class of linear unbiased estimators, which is quite restrictive. Depending on the distribution of the error terms ε, other, non-linear estimators may provide better results than OLS.
Assuming normality
[edit]The properties listed so far are all valid regardless of the underlying distribution of the error terms. However, if you are willing to assume that the normality assumption holds (that is, that ε ~ N(0, σ2In)), then additional properties of the OLS estimators can be stated.
The estimator is normally distributed, with mean and variance as given before:[26]

This estimator reaches the Cramér–Rao bound for the model, and thus is optimal in the class of all unbiased estimators.[17] Note that unlike the Gauss–Markov theorem, this result establishes optimality among both linear and non-linear estimators, but only in the case of normally distributed error terms.
The estimator s2 will be proportional to the chi-squared distribution:[27]

The variance of this estimator is equal to 2σ4/(n − p), which does not attain the Cramér–Rao bound of 2σ4/n. However it was shown that there are no unbiased estimators of σ2 with variance smaller than that of the estimator s2.[28] If we are willing to allow biased estimators, and consider the class of estimators that are proportional to the sum of squared residuals (SSR) of the model, then the best (in the sense of the mean squared error) estimator in this class will be ~σ2 = SSR / (n − p + 2), which even beats the Cramér–Rao bound in case when there is only one regressor (p = 1).[29]
Moreover, the estimators and s2 are independent,[30] the fact which comes in useful when constructing the t- and F-tests for the regression.
Influential observations
[edit]As was mentioned before, the estimator is linear in y, meaning that it represents a linear combination of the dependent variables yi. The weights in this linear combination are functions of the regressors X, and generally are unequal. The observations with high weights are called influential because they have a more pronounced effect on the value of the estimator.
To analyze which observations are influential we remove a specific j-th observation and consider how much the estimated quantities are going to change (similarly to the jackknife method). It can be shown that the change in the OLS estimator for β will be equal to [31]

where hj = xjT (XTX)−1xj is the j-th diagonal element of the hat matrix P, and xj is the vector of regressors corresponding to the j-th observation. Similarly, the change in the predicted value for j-th observation resulting from omitting that observation from the dataset will be equal to [31]

From the properties of the hat matrix, 0 ≤ hj ≤ 1, and they sum up to p, so that on average hj ≈ p/n. These quantities hj are called the leverages, and observations with high hj are called leverage points.[32] Usually the observations with high leverage ought to be scrutinized more carefully, in case they are erroneous, or outliers, or in some other way atypical of the rest of the dataset.
Partitioned regression
[edit]Sometimes the variables and corresponding parameters in the regression can be logically split into two groups, so that the regression takes form

where X1 and X2 have dimensions n×p1, n×p2, and β1, β2 are p1×1 and p2×1 vectors, with p1 + p2 = p.
The Frisch–Waugh–Lovell theorem states that in this regression the residuals and the OLS estimate will be numerically identical to the residuals and the OLS estimate for β2 in the following regression:[33]



where M1 is the annihilator matrix for regressors X1.
The theorem can be used to establish a number of theoretical results. For example, having a regression with a constant and another regressor is equivalent to subtracting the means from the dependent variable and the regressor and then running the regression for the de-meaned variables but without the constant term.
Constrained estimation
[edit]Suppose it is known that the coefficients in the regression satisfy a system of linear equations

where Q is a p×q matrix of full rank, and c is a q×1 vector of known constants, where q < p. In this case least squares estimation is equivalent to minimizing the sum of squared residuals of the model subject to the constraint A. The constrained least squares (CLS) estimator can be given by an explicit formula:[34]

This expression for the constrained estimator is valid as long as the matrix XTX is invertible. It was assumed from the beginning of this article that this matrix is of full rank, and it was noted that when the rank condition fails, β will not be identifiable. However it may happen that adding the restriction A makes β identifiable, in which case one would like to find the formula for the estimator. The estimator is equal to [35]

where R is a p×(p − q) matrix such that the matrix [Q R] is non-singular, and RTQ = 0. Such a matrix can always be found, although generally it is not unique. The second formula coincides with the first in case when XTX is invertible.[35]
Large sample properties
[edit]The least squares estimators are point estimates of the linear regression model parameters β. However, generally we also want to know how close those estimates might be to the true values of parameters. In other words, we want to construct the interval estimates.
Since we have not made any assumption about the distribution of error term εi, it is impossible to infer the distribution of the estimators and . Nevertheless, we can apply the central limit theorem to derive their asymptotic properties as sample size n goes to infinity. While the sample size is necessarily finite, it is customary to assume that n is "large enough" so that the true distribution of the OLS estimator is close to its asymptotic limit.

We can show that under the model assumptions, the least squares estimator for β is consistent (that is converges in probability to β) and asymptotically normal:[proof]

where

Intervals
[edit]Using this asymptotic distribution, approximate two-sided confidence intervals for the j-th component of the vector can be constructed as
- at the 1 − α confidence level,
![{\displaystyle \beta _{j}\in {\bigg [}\ {\hat {\beta }}_{j}\pm q_{1-{\frac {\alpha }{2}}}^{{\mathcal {N}}(0,1)}\!{\sqrt {{\hat {\sigma }}^{2}\left[Q_{xx}^{-1}\right]_{jj}}}\ {\bigg ]}}](https://wikimedia.riteme.site/api/rest_v1/media/math/render/svg/cf79688aac9f662ff39253fbfb0d234246d370e5)
where q denotes the quantile function of standard normal distribution, and [·]jj is the j-th diagonal element of a matrix.
Similarly, the least squares estimator for σ2 is also consistent and asymptotically normal (provided that the fourth moment of εi exists) with limiting distribution
![{\displaystyle ({\hat {\sigma }}^{2}-\sigma ^{2})\ {\xrightarrow {d}}\ {\mathcal {N}}\left(0,\;\operatorname {E} \left[\varepsilon _{i}^{4}\right]-\sigma ^{4}\right).}](https://wikimedia.riteme.site/api/rest_v1/media/math/render/svg/7c909dea2a4f0bf40e253680b953d1bfbb66298f)
These asymptotic distributions can be used for prediction, testing hypotheses, constructing other estimators, etc.. As an example consider the problem of prediction. Suppose is some point within the domain of distribution of the regressors, and one wants to know what the response variable would have been at that point. The mean response is the quantity , whereas the predicted response is . Clearly the predicted response is a random variable, its distribution can be derived from that of :




which allows construct confidence intervals for mean response to be constructed:

- at the 1 − α confidence level.
![{\displaystyle y_{0}\in \left[\ x_{0}^{\mathrm {T} }{\hat {\beta }}\pm q_{1-{\frac {\alpha }{2}}}^{{\mathcal {N}}(0,1)}\!{\sqrt {{\hat {\sigma }}^{2}x_{0}^{\mathrm {T} }Q_{xx}^{-1}x_{0}}}\ \right]}](https://wikimedia.riteme.site/api/rest_v1/media/math/render/svg/cf86d7a311c97d35fb6e039c3cd74bc9f3e752bf)
Hypothesis testing
[edit]This section needs expansion. You can help by adding to it. (February 2017) |
Two hypothesis tests are particularly widely used. First, one wants to know if the estimated regression equation is any better than simply predicting that all values of the response variable equal its sample mean (if not, it is said to have no explanatory power). The null hypothesis of no explanatory value of the estimated regression is tested using an F-test. If the calculated F-value is found to be large enough to exceed its critical value for the pre-chosen level of significance, the null hypothesis is rejected and the alternative hypothesis, that the regression has explanatory power, is accepted. Otherwise, the null hypothesis of no explanatory power is accepted.
Second, for each explanatory variable of interest, one wants to know whether its estimated coefficient differs significantly from zero—that is, whether this particular explanatory variable in fact has explanatory power in predicting the response variable. Here the null hypothesis is that the true coefficient is zero. This hypothesis is tested by computing the coefficient's t-statistic, as the ratio of the coefficient estimate to its standard error. If the t-statistic is larger than a predetermined value, the null hypothesis is rejected and the variable is found to have explanatory power, with its coefficient significantly different from zero. Otherwise, the null hypothesis of a zero value of the true coefficient is accepted.
In addition, the Chow test is used to test whether two subsamples both have the same underlying true coefficient values. The sum of squared residuals of regressions on each of the subsets and on the combined data set are compared by computing an F-statistic; if this exceeds a critical value, the null hypothesis of no difference between the two subsets is rejected; otherwise, it is accepted.
Example with real data
[edit]The following data set gives average heights and weights for American women aged 30–39 (source: The World Almanac and Book of Facts, 1975).
Height (m) 1.47 1.50 1.52 1.55 1.57 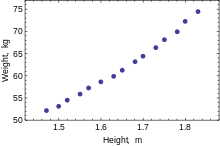
Scatterplot of the data, the relationship is slightly curved but close to linear Weight (kg) 52.21 53.12 54.48 55.84 57.20 Height (m) 1.60 1.63 1.65 1.68 1.70 Weight (kg) 58.57 59.93 61.29 63.11 64.47 Height (m) 1.73 1.75 1.78 1.80 1.83 Weight (kg) 66.28 68.10 69.92 72.19 74.46

When only one dependent variable is being modeled, a scatterplot will suggest the form and strength of the relationship between the dependent variable and regressors. It might also reveal outliers, heteroscedasticity, and other aspects of the data that may complicate the interpretation of a fitted regression model. The scatterplot suggests that the relationship is strong and can be approximated as a quadratic function. OLS can handle non-linear relationships by introducing the regressor HEIGHT2. The regression model then becomes a multiple linear model:


The output from most popular statistical packages will look similar to this:
Method Least squares Dependent variable WEIGHT Observations 15
Parameter Value Std error t-statistic p-value
128.8128 16.3083 7.8986 0.0000 –143.1620 19.8332 –7.2183 0.0000 61.9603 6.0084 10.3122 0.0000
R2 0.9989 S.E. of regression 0.2516 Adjusted R2 0.9987 Model sum-of-sq. 692.61 Log-likelihood 1.0890 Residual sum-of-sq. 0.7595 Durbin–Watson stat. 2.1013 Total sum-of-sq. 693.37 Akaike criterion 0.2548 F-statistic 5471.2 Schwarz criterion 0.3964 p-value (F-stat) 0.0000


In this table:
- The Value column gives the least squares estimates of parameters βj
- The Std error column shows standard errors of each coefficient estimate:
- The t-statistic and p-value columns are testing whether any of the coefficients might be equal to zero. The t-statistic is calculated simply as . If the errors ε follow a normal distribution, t follows a Student-t distribution. Under weaker conditions, t is asymptotically normal. Large values of t indicate that the null hypothesis can be rejected and that the corresponding coefficient is not zero. The second column, p-value, expresses the results of the hypothesis test as a significance level. Conventionally, p-values smaller than 0.05 are taken as evidence that the population coefficient is nonzero.
- R-squared is the coefficient of determination indicating goodness-of-fit of the regression. This statistic will be equal to one if fit is perfect, and to zero when regressors X have no explanatory power whatsoever. This is a biased estimate of the population R-squared, and will never decrease if additional regressors are added, even if they are irrelevant.
- Adjusted R-squared is a slightly modified version of , designed to penalize for the excess number of regressors which do not add to the explanatory power of the regression. This statistic is always smaller than , can decrease as new regressors are added, and even be negative for poorly fitting models:
![{\displaystyle {\hat {\sigma }}_{j}=\left({\hat {\sigma }}^{2}\left[Q_{xx}^{-1}\right]_{jj}\right)^{\frac {1}{2}}}](https://wikimedia.riteme.site/api/rest_v1/media/math/render/svg/5087e66171bf3ef9ad3ac75decdd715274919669)



- Log-likelihood is calculated under the assumption that errors follow normal distribution. Even though the assumption is not very reasonable, this statistic may still find its use in conducting LR tests.
- Durbin–Watson statistic tests whether there is any evidence of serial correlation between the residuals. As a rule of thumb, the value smaller than 2 will be an evidence of positive correlation.
- Akaike information criterion and Schwarz criterion are both used for model selection. Generally when comparing two alternative models, smaller values of one of these criteria will indicate a better model.[36]
- Standard error of regression is an estimate of σ, standard error of the error term.
- Total sum of squares, model sum of squared, and residual sum of squares tell us how much of the initial variation in the sample were explained by the regression.
- F-statistic tries to test the hypothesis that all coefficients (except the intercept) are equal to zero. This statistic has F(p–1,n–p) distribution under the null hypothesis and normality assumption, and its p-value indicates probability that the hypothesis is indeed true. Note that when errors are not normal this statistic becomes invalid, and other tests such as Wald test or LR test should be used.

Ordinary least squares analysis often includes the use of diagnostic plots designed to detect departures of the data from the assumed form of the model. These are some of the common diagnostic plots:
- Residuals against the explanatory variables in the model. A non-linear relation between these variables suggests that the linearity of the conditional mean function may not hold. Different levels of variability in the residuals for different levels of the explanatory variables suggests possible heteroscedasticity.
- Residuals against explanatory variables not in the model. Any relation of the residuals to these variables would suggest considering these variables for inclusion in the model.
- Residuals against the fitted values, .
- Residuals against the preceding residual. This plot may identify serial correlations in the residuals.

An important consideration when carrying out statistical inference using regression models is how the data were sampled. In this example, the data are averages rather than measurements on individual women. The fit of the model is very good, but this does not imply that the weight of an individual woman can be predicted with high accuracy based only on her height.
Sensitivity to rounding
[edit]This example also demonstrates that coefficients determined by these calculations are sensitive to how the data is prepared. The heights were originally given rounded to the nearest inch and have been converted and rounded to the nearest centimetre. Since the conversion factor is one inch to 2.54 cm this is not an exact conversion. The original inches can be recovered by Round(x/0.0254) and then re-converted to metric without rounding. If this is done the results become:
| Const | Height | Height2 | |
|---|---|---|---|
| Converted to metric with rounding. | 128.8128 | −143.162 | 61.96033 |
| Converted to metric without rounding. | 119.0205 | −131.5076 | 58.5046 |

Using either of these equations to predict the weight of a 5' 6" (1.6764 m) woman gives similar values: 62.94 kg with rounding vs. 62.98 kg without rounding. Thus a seemingly small variation in the data has a real effect on the coefficients but a small effect on the results of the equation.
While this may look innocuous in the middle of the data range it could become significant at the extremes or in the case where the fitted model is used to project outside the data range (extrapolation).
This highlights a common error: this example is an abuse of OLS which inherently requires that the errors in the independent variable (in this case height) are zero or at least negligible. The initial rounding to nearest inch plus any actual measurement errors constitute a finite and non-negligible error. As a result, the fitted parameters are not the best estimates they are presumed to be. Though not totally spurious the error in the estimation will depend upon relative size of the x and y errors.
Another example with less real data
[edit]Problem statement
[edit]We can use the least square mechanism to figure out the equation of a two body orbit in polar base co-ordinates. The equation typically used is where is the radius of how far the object is from one of the bodies. In the equation the parameters and are used to determine the path of the orbit. We have measured the following data.



| (in degrees) | 43 | 45 | 52 | 93 | 108 | 116 |
|---|---|---|---|---|---|---|
| 4.7126 | 4.5542 | 4.0419 | 2.2187 | 1.8910 | 1.7599 |

We need to find the least-squares approximation of and for the given data.
Solution
[edit]First we need to represent e and p in a linear form. So we are going to rewrite the equation as . Furthermore, one could fit for apsides by expanding with an extra parameter as , which is linear in both and in the extra basis function , used to extra . We use the original two-parameter form to represent our observational data as:





where is and is and is constructed by the first column being the coefficient of and the second column being the coefficient of and is the values for the respective so and










On solving we get

so and


See also
[edit]- Bayesian least squares
- Fama–MacBeth regression
- Nonlinear least squares
- Numerical methods for linear least squares
- Nonlinear system identification
References
[edit]- ^ "The Origins of Ordinary Least Squares Assumptions". Feature Column. 2022-03-01. Retrieved 2024-05-16.
- ^ "What is a complete list of the usual assumptions for linear regression?". Cross Validated. Retrieved 2022-09-28.
- ^ Goldberger, Arthur S. (1964). "Classical Linear Regression". Econometric Theory. New York: John Wiley & Sons. pp. 158. ISBN 0-471-31101-4.
- ^ Hayashi, Fumio (2000). Econometrics. Princeton University Press. p. 15.
- ^ Hayashi (2000, page 18).
- ^ Ghilani, Charles D.; Paul r. Wolf, Ph. D. (12 June 2006). Adjustment Computations: Spatial Data Analysis. ISBN 9780471697282.
- ^ Hofmann-Wellenhof, Bernhard; Lichtenegger, Herbert; Wasle, Elmar (20 November 2007). GNSS – Global Navigation Satellite Systems: GPS, GLONASS, Galileo, and more. ISBN 9783211730171.
- ^ Xu, Guochang (5 October 2007). GPS: Theory, Algorithms and Applications. ISBN 9783540727156.
- ^ a b Hayashi (2000, page 19)
- ^ Hoaglin, David C.; Welsch, Roy E. (1978). "The Hat Matrix in Regression and ANOVA". The American Statistician. 32 (1): 17–22. doi:10.1080/00031305.1978.10479237. hdl:1721.1/1920. ISSN 0003-1305.
- ^ Julian Faraway (2000), Practical Regression and Anova using R
- ^ Kenney, J.; Keeping, E. S. (1963). Mathematics of Statistics. van Nostrand. p. 187.
- ^ Zwillinger, D. (1995). Standard Mathematical Tables and Formulae. Chapman&Hall/CRC. p. 626. ISBN 0-8493-2479-3.
- ^ Hayashi (2000, page 20)
- ^ Akbarzadeh, Vahab (7 May 2014). "Line Estimation".
- ^ Hayashi (2000, page 49)
- ^ a b Hayashi (2000, page 52)
- ^ Hayashi (2000, page 7)
- ^ Hayashi (2000, page 187)
- ^ a b Hayashi (2000, page 10)
- ^ Hayashi (2000, page 34)
- ^ Williams, M. N; Grajales, C. A. G; Kurkiewicz, D (2013). "Assumptions of multiple regression: Correcting two misconceptions". Practical Assessment, Research & Evaluation. 18 (11).
- ^ "Memento on EViews Output" (PDF). Retrieved 28 December 2020.
- ^ Hayashi (2000, pages 27, 30)
- ^ a b c Hayashi (2000, page 27)
- ^ Amemiya, Takeshi (1985). Advanced Econometrics. Harvard University Press. p. 13. ISBN 9780674005600.
- ^ Amemiya (1985, page 14)
- ^ Rao, C. R. (1973). Linear Statistical Inference and its Applications (Second ed.). New York: J. Wiley & Sons. p. 319. ISBN 0-471-70823-2.
- ^ Amemiya (1985, page 20)
- ^ Amemiya (1985, page 27)
- ^ a b Davidson, Russell; MacKinnon, James G. (1993). Estimation and Inference in Econometrics. New York: Oxford University Press. p. 33. ISBN 0-19-506011-3.
- ^ Davidson & MacKinnon (1993, page 36)
- ^ Davidson & MacKinnon (1993, page 20)
- ^ Amemiya (1985, page 21)
- ^ a b Amemiya (1985, page 22)
- ^ Burnham, Kenneth P.; David Anderson (2002). Model Selection and Multi-Model Inference (2nd ed.). Springer. ISBN 0-387-95364-7.
Further reading
[edit]- Dougherty, Christopher (2002). Introduction to Econometrics (2nd ed.). New York: Oxford University Press. pp. 48–113. ISBN 0-19-877643-8.
- Gujarati, Damodar N.; Porter, Dawn C. (2009). Basic Econometics (Fifth ed.). Boston: McGraw-Hill Irwin. pp. 55–96. ISBN 978-0-07-337577-9.
- Heij, Christiaan; Boer, Paul; Franses, Philip H.; Kloek, Teun; van Dijk, Herman K. (2004). Econometric Methods with Applications in Business and Economics (1st ed.). Oxford: Oxford University Press. pp. 76–115. ISBN 978-0-19-926801-6.
- Hill, R. Carter; Griffiths, William E.; Lim, Guay C. (2008). Principles of Econometrics (3rd ed.). Hoboken, NJ: John Wiley & Sons. pp. 8–47. ISBN 978-0-471-72360-8.
- Wooldridge, Jeffrey (2008). "The Simple Regression Model". Introductory Econometrics: A Modern Approach (4th ed.). Mason, OH: Cengage Learning. pp. 22–67. ISBN 978-0-324-58162-1.
| Computational statistics | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Correlation and dependence | |||||||||
| Regression analysis | |||||||||
| Regression as a statistical model |
| ||||||||
| Decomposition of variance | |||||||||
| Model exploration | |||||||||
| Background | |||||||||
| Design of experiments | |||||||||
| Numerical approximation | |||||||||
| Applications | |||||||||